Şimdiye kadar CPU’ların executable dosyalardan yüklenen makine kodunu nasıl yürüttüğünü, ring tabanlı güvenliğin ne olduğunu ve syscall’ların nasıl çalıştığını gördük. Bu bölümde ise Linux kernel’ının içine biraz daha dalıp programların gerçekten nasıl yüklendiğini ve çalıştırıldığını anlamaya çalışacağız.
Kernel kaynak koduyla ilk kez karşılaşıyorsan: Aşağıda göreceğin kod parçaları korkutucu görünebilir, ama endişelenme. Her bloğu adım adım açıklayacağız; amaç sadece “kernel nasıl çalışıyor” hissini kazandırmak, seni kernel geliştiricisi yapmak değil. Hazırsan başlayalım.
Bu bölümde neyi çözüyoruz?
execve çağrısının mevcut process’i yeni bir programla nasıl değiştirdiğini göreceğiz.
Kernel’ın dosya formatını nasıl tanıdığını ve shebang satırını nasıl ele aldığını anlayacağız.
“Terminalden çalıştırdım” ile “CPU gerçekten yeni koda atladı” arasındaki köprüyü kuracağız.
Özellikle x86-64 üzerindeki Linux’a bakacağız. Neden?
Linux, masaüstünden mobile ve sunucuya kadar geniş kullanım alanına sahip tam teşekküllü bir üretim işletim sistemidir. Üstelik açık kaynak olduğu için doğrudan kaynak koda bakarak ilerlemek çok kolaydır. Bu makalede kernel koduna bol bol referans vereceğim.
x86-64, modern masaüstü bilgisayarların büyük kısmında kullanılan mimaridir ve pek çok kodun hedefidir. Burada göreceğimiz x86-64’e özgü ayrıntıların önemli kısmı yine de daha genel fikirlere açılır.
Öğreneceğimiz şeylerin çoğu, ayrıntılar değişse de başka işletim sistemlerine ve mimarilere de kolayca genellenebilir.
Exec Syscall’larının Temel Davranışı
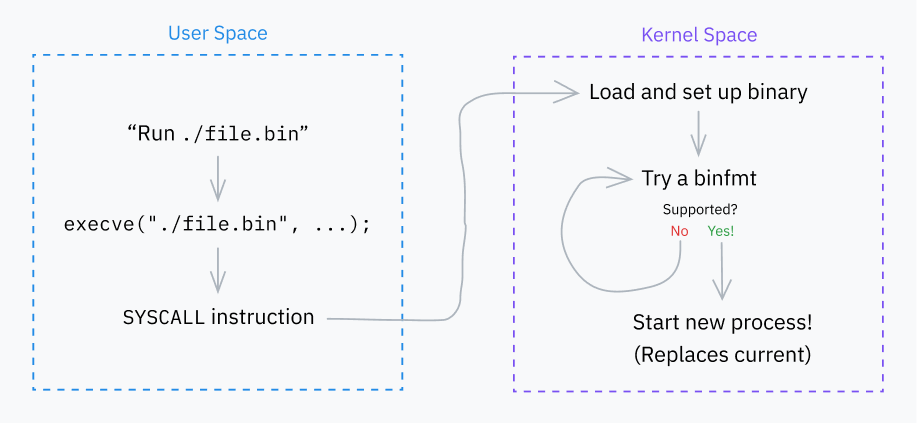
Çok önemli bir sistem çağrısıyla başlayalım: execve. Bir programı yükler ve başarılı olursa mevcut işlemi o programla değiştirir. Birkaç sistem çağrısı (execlp, execvpe, vb.) daha mevcut, ancak hepsi çeşitli şekillerde execve‘nin üzerinde katmanlanıyor.
Bir not: execveat
Linux’ta execve ve execveat kullanıcıya görünen ayrı syscall’lardır, ama kernel içinde büyük ölçüde ortak bir yardımcı yola bağlanırlar: do_execveat_common. execveat bazı ek seçeneklerle program yürütmeye izin verir. Biz sadelik adına çoğunlukla execve üzerinden konuşacağız; pratikte fark, kernel’ın ortak helper’a hangi dosya descriptor’ı ve flag’lerle girdiğidir.
ve ne demek diye merak ediyorsan: v, argüman vektörü olan argv‘yi; e ise environment vektörü olan envp‘yi temsil eder. Diğer exec varyantları da farklı çağrı imzalarını son eklerle ayırt eder. execveat içindeki at ise, programın hangi konuma göre çalıştırılacağını belirtebildiği için oradadır.
filename, çalıştırılacak programın yolunu belirtir.
argv, null-terminated bir argüman listesidir; yani son öğe null pointer’dır. C’deki main fonksiyonunda gördüğün argc değeri aslında daha sonra bu listeden hesaplanır.
envp ise programın ortam değişkenlerini taşıyan, yine null-terminated başka bir listedir. Bunlar… geleneksel olarak KEY=VALUE çiftleridir. Geleneksel olarak. Bilgisayarları seviyorum.
Küçük ama önemli bir ayrıntı: Bir programın ilk argümanının program adı olması diye bildiğimiz şey sadece bir konvansiyondur. execve bunu kendiliğinden ayarlamaz. İlk argüman, çağıran kod argv içine ne koyduysa odur; ister program adı olsun ister bambaşka bir şey.
Yine de ilginç biçimde, bazı kod yollarında execve ve çevresindeki logic, argv[0]‘ın program adını temsil ettiğini varsayar. Birazdan interpreted dillerden söz ederken bunun bir örneğini göreceğiz.
Adım 0: Tanım
Sistem çağrılarının nasıl çalıştığını zaten biliyoruz, ancak gerçek dünyadan bir kod örneğini hiç görmedik! execve‘nin başlık altında nasıl tanımlandığını görmek için Linux çekirdeğinin kaynak koduna bakalım:
SYSCALL_DEFINE3, 3 bağımsız değişkenli sistem çağrısının kodunu tanımlamak için kullanılan bir makrodur.
arity’nin makro adına neden sabit kodlandığını merak ettim; Google’da araştırdım ve bunun CVE-2009-0029 gibi güvenlik açıklarını kalıcı olarak önlemek için tasarlanmış bir mimari karar olduğunu öğrendim. Arity’nin makroya sabit kodlanması, derleyici seviyesinde tüm argümanların doğru tiplere zorlanmasını (type-casting) ve güvenli bir şekilde işaret uzatılmasını (sign-extension) sağlar.
Dosya adı argümanı, dizeyi kullanıcı alanından çekirdek alanına kopyalayan ve bazı kullanım izleme işlemleri yapan bir getname() işlevine iletilir. include/linux/fs.h içinde tanımlanan bir filename yapısını döndürür. Kullanıcı alanındaki orijinal dizeye yönelik bir işaretçinin yanı sıra, çekirdek alanına kopyalanan değere yönelik yeni bir işaretçiyi de saklar:
struct filename {constchar*name; /* pointer to actual string */const __user char*uptr; /* original userland pointer */int refcnt;struct audit_names *aname;constchar iname[];};
execve sistem çağrısı daha sonra bir do_execve() işlevini çağırır. Bu da bazı varsayılanlarla do_execveat_common() öğesini çağırır. Daha önce bahsettiğim execveat sistem çağrısı da aynı ortak helper’a gider, ama kullanıcı tarafından sağlanan daha fazla seçenekten geçer.
Aşağıdaki kod parçasına hem do_execve hem de do_execveat tanımlarını ekledim:
execveat çağrısında bir file descriptor (bir kaynağa işaret eden kimlik türü) syscall’a ve oradan da do_execveat_common fonksiyonuna geçer. Bu descriptor, programın hangi dizine göre yürütüleceğini belirler.
execve tarafında ise file descriptor argümanı için özel bir değer kullanılır: AT_FDCWD. Bu, Linux kernel’ında path’lerin current working directory’ye göre yorumlanmasını söyleyen ortak bir sabittir. File descriptor alan fonksiyonlarda genelde if (fd == AT_FDCWD) { /* special codepath */ } benzeri açık bir kontrol görürsün.
Adım 1: Kurulum
Artık çekirdek işlev yürütme programının yürütülmesi olan do_execveat_common‘ye ulaştık. Bu işlevin ne yaptığına dair daha büyük bir resim görünümü elde etmek için koda bakmaktan kısa bir adım atacağız.
do_execveat_common‘nin ilk büyük işi linux_binprm adında bir yapı kurmaktır. Yapı tanımının tamamının bir kopyasını eklemeyeceğim, ancak incelenecek birkaç önemli alan var:
Yeni programa sanal bellek yönetimini hazırlamak için mm_struct ve vm_area_struct gibi veri yapıları tanımlanmıştır.
argc ve envc hesaplanır ve programa aktarılmak üzere saklanır.
filename ve interp sırasıyla programın ve yorumlayıcısının dosya adını saklar. Bunlar birbirine eşit olarak başlar ancak bazı durumlarda değişebilir: Böyle bir durum, yorumlanmış komut dosyalarının shebang ile çalıştırılmasıdır. Örneğin bir Python programını çalıştırırken, filename kaynak dosyayı işaret eder ancak interp Python yorumlayıcısının yoludur.
buf, yürütülecek dosyanın ilk 256 baytıyla dolu bir dizidir. Dosyanın formatını tespit etmek ve komut dosyası shebanglarını yüklemek için kullanılır.
(TIL: binprm, binary program anlamına gelir.)
execve çoğu hata için eski programı güvenli tarafta tutmaya çalışır: Kernel uygun bir binfmt bulamazsa, yetki yetersizse ya da hazırlık erken aşamada bozulursa syscall hata kodu döndürür ve eski program devam eder. Fakat Linux man page’lerinin de uyardığı gibi, nadir durumlarda eski program yıkıldıktan sonra hata oluşabilir; bu point of no return sonrası artık eski programa sağlıklı şekilde dönülemez ve process sonlandırılabilir. Yani kullanıcı açısından execve “başarırsa geri dönmez, erken başarısız olursa hata döndürür” diye düşünülür; kernel içi gerçeklikte küçük ama önemli bir gri alan vardır.
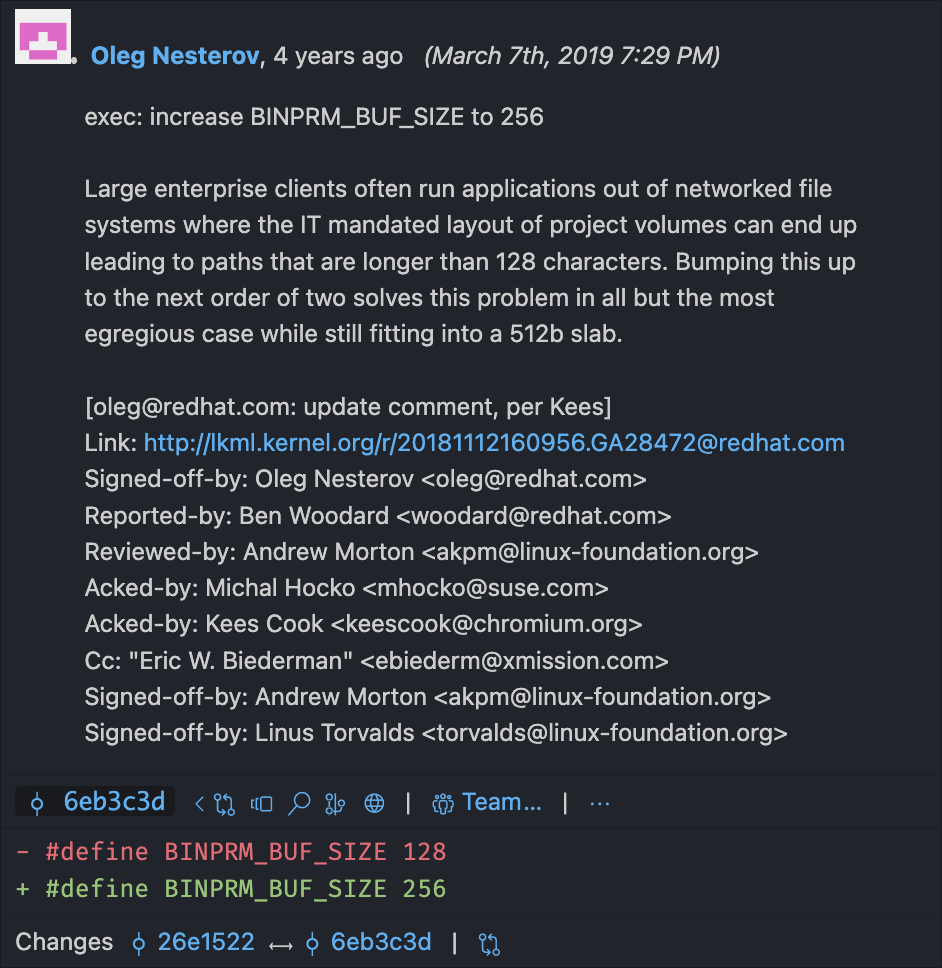
Gördüğümüz gibi uzunluk BINPRM_BUF_SIZE sabitiyle tanımlanıyor. Kod tabanında bunu arattığında, include/uapi/linux/binfmts.h içinde şu tanıma ulaşıyorsun:
Böylece çekirdek, yürütülen dosyanın açılış 256 baytını bu bellek arabelleğine yükler.
Bir yana: UAPI nedir?
Yukarıdaki yolun /uapi/ içerdiğini fark etmiş olabilirsin. Peki bu sabit neden linux_binprm yapısıyla aynı dosyada tanımlanmıyor?
UAPI, “kullanıcı alanı API’si” anlamına gelir. Bu durumda, birisinin arabellek uzunluğunun çekirdeğin genel API’sinin bir parçası olması gerektiğine karar verdiği anlamına gelir. Teorik olarak, UAPI’nin kullanıcı alanına açık olduğu her şey ve UAPI olmayan her şey çekirdek koduna özeldir.
Çekirdek ve kullanıcı alanı kodu başlangıçta tek bir karmakarışık kütle halinde bir arada mevcuttu. 2012 yılında, sürdürülebilirliği iyileştirme girişimi olarak UAPI kodu ayrı bir dizinde yeniden düzenlendi.
Adım 2: Binfmt’ler
Çekirdeğin bir sonraki büyük işi bir grup “binfmt” (ikili format) işleyicisini yinelemektir. Bu işleyiciler fs/binfmt_elf.c ve fs/binfmt_flat.c gibi dosyalarda tanımlanır. Çekirdek modülleri ayrıca havuza kendi binfmt işleyicilerini de ekleyebilir.
Her işleyici, linux_binprm yapısını alan bir load_binary() işlevini kullanıma sunar ve işleyicinin programın formatını anlayıp anlamadığını kontrol eder.
Bu genellikle arabellekte sihirli sayılar aramayı, programın başlangıcının kodunu çözmeye çalışmayı (yine ara bellekten) ve/veya dosya uzantısını kontrol etmeyi içerir. İşleyici formatı destekliyorsa programı yürütmeye hazırlar ve bir başarı kodu döndürür. Aksi halde erkenden çıkar ve bir hata kodu döndürür.
Çekirdek, başarılı olana ulaşana kadar her binfmt’nin load_binary() işlevini dener. Bazen bunlar yinelemeli olarak çalışır; örneğin, bir betiğin belirlenmiş bir yorumlayıcısı varsa ve bu yorumlayıcının kendisi de bir betikse, hiyerarşi binfmt_script > binfmt_script > binfmt_elf olabilir (burada ELF, zincirin sonunda çalıştırılabilir formattır).
Format Vurgulama: Komut Dosyaları
Linux’un desteklediği pek çok formattan binfmt_script özellikle bahsetmek istediğim ilk format.
Hiç shebang satırı gördün mü? Hani bazı script’lerin en başında interpreter yolunu söyleyen şu satır:
1
#!/bin/bash
Ben uzun süre bunun shell tarafından ele alındığını sanmıştım. Meğer öyle değilmiş. Shebang’ler aslında kernel özelliği ve script’ler de diğer programlarla aynı syscall’lar üzerinden yürütülüyor. Bilgisayarlar gerçekten çok havalı.
fs/binfmt_script.c dosyasının, bir dosyanın #! ile başlayıp başlamadığını nasıl kontrol ettiğine bak:
/* Not ours to exec if we don't start with "#!". */if ((bprm->buf[0] !='#') || (bprm->buf[1] !='!'))return-ENOEXEC;
Dosya bir shebang ile başlıyorsa, binfmt işleyicisi yorumlayıcı yolunu ve yoldan sonraki boşlukla ayrılmış bağımsız değişkenleri okur. Yeni bir satıra veya arabelleğin sonuna ulaştığında durur.
Burada iki ilginç, riskli şey oluyor.
Birincisi, linux_binprm içindeki ve dosyanın ilk 256 baytıyla doldurulan buffer’ı hatırlıyor musun? Yürütülebilir formatı tespit etmek için kullanılan bu aynı buffer, binfmt_script içinde shebang satırlarını okumak için de kullanılıyor.
Araştırma yaparken buffer’ın bir zamanlar 128 bayt olduğunu söyleyen kaynaklara rastladım. Sonra fark ettim ki bu uzunluk sonradan 256’ya çıkarılmış. Nedenini merak edip BINPRM_BUF_SIZE satırı için Git blame baktım. Sonuç şuydu:
BİLGİSAYARLAR ÇOK HARİKA.
Shebang kernel tarafından işlendiği ve tüm dosya yerine yalnızca buf içinden okunduğu için, interpreter satırı sabit bir üst sınıra takılır. Linux 5.1’den beri #! sonrasında okunan metin sınırı 255 karakterdir; daha eski kernel’larda bu sınır 127 karakterdi. BINPRM_BUF_SIZE = 256 teknik detayı buradan gelir. Satır bu sınıra sığmazsa fazla kısım yok sayılır; kernel yarım kalan yolu/argümanı denediği için sonuç çoğu zaman ENOENT veya benzeri bir execve hatasıdır — veri sadece kaybolup program sessizce doğru çalışmaya devam etmez.
Böyle bir bug yaşadığını düşün. Kodunu bozan şeyin kök nedenini arıyorsun. Sonra problemin, Linux kernel’ının derinliklerinde duran bir buffer uzunluğu sınırı olduğunu öğreniyorsun. Büyük kurumsal path’lerde bir kısmın gizemli biçimde silindiğini fark eden bir sonraki BT çalışanına şimdiden sabır diliyorum.
İkinci riskli şey: Az önce argv[0]‘ın program adı olmasının sadece bir konvansiyon olduğunu ve çağıranın istediği argv‘yi verebileceğini konuşmuştuk ya? İşte binfmt_script, argv[0]‘ın program adı olduğunu varsayan yerlerden biri.
Bu handler, önce argv[0]‘ı siler ve ardından argv‘nin başına şunları ekler:
argv güncellendikten sonra handler, linux_binprm.interp değerini interpreter yoluna ayarlayarak yürütme hazırlığını tamamlar. Son olarak programın başarıyla hazırlandığını göstermek için 0 döndürür.
Format Vurgulama: Çeşitli Yorumlayıcılar
Bir başka ilginç işleyici ise binfmt_misc. /proc/sys/fs/binfmt_misc/ adresine özel bir dosya sistemi monte ederek, kullanıcı alanı yapılandırması aracılığıyla bazı sınırlı formatları ekleme olanağını açar. Programlar, kendi işleyicilerini eklemek için bu dizindeki dosyalara özel olarak biçimlendirilmiş yazma işlemleri gerçekleştirebilir. Her konfigürasyon girişi şunları belirtir:
Dosya formatları nasıl tespit edilir. Bu, belirli bir konumdaki sihirli bir sayıyı veya aranacak bir dosya uzantısını belirtebilir.
Çalıştırılabilir bir yorumlayıcının yolu. Yorumlayıcı argümanlarını belirtmenin bir yolu yoktur, bu nedenle eğer istenirse bir sarmalayıcı komut dosyasına ihtiyaç vardır.
binfmt_misc‘nin argv‘yi nasıl güncellediğini belirten bir tane de dahil olmak üzere bazı yapılandırma işaretleri.
Bu binfmt_misc sistemi geçmişte Java class/JAR dosyaları gibi formatlar için kullanılabildiği gibi, bugün pratikte QEMU user emulation ve container/multi-arch geliştirme akışlarında da sık karşına çıkar: örneğin ARM için derlenmiş bir binary’yi x86-64 makinede uygun QEMU interpreter’ına otomatik yönlendirmek mümkün olur. Bazı sistemlerde özel bytecode, .pyc benzeri dosyalar veya kurum içi executable formatları da bu yolla bir kullanıcı alanı yorumlayıcısına aktarılabilir.
Bu, program yükleyicilerinin yüksek ayrıcalıklı çekirdek kodu yazmaya gerek kalmadan kendi formatları için destek eklemelerine izin vermenin oldukça güzel bir yoludur.
Sonunda (Linkin Park Şarkısı Olan Değil)
Bir exec sistem çağrısı pratikte genellikle iki yoldan biriyle sonuçlanır:
Belki de birkaç katmandan oluşan komut dosyası yorumlayıcılarından sonra, sonunda anlayabileceği yürütülebilir bir ikili formata ulaşacak ve bu kodu çalıştıracaktır. Bu noktada eski kod değiştirildi.
… ya da tüm seçeneklerini tüketecek ve çağıran programa, kuyruğu bacaklarının arasında olacak şekilde bir hata kodu döndürecektir.
Nadir kernel-içi hata yollarında point of no return sonrası eski programa dönülemeyeceğini az önce not etmiştik; bu ayrıntı günlük mental modelde değil, doğruluk payı olarak aklının köşesinde dursun.
Unix benzeri bir sistem kullandıysan, terminalden çalıştırılan shell script’lerin bazen ne shebang ne de .sh uzantısı olmadan yine de yürütüldüğünü fark etmiş olabilirsin. Elinin altında Unix benzeri bir terminal varsa hemen deneyebilirsin:
(chmod +x, işletim sistemine dosyanın çalıştırılabilir olduğunu söyler. Bunu yapmazsan dosyayı yürütemezsin.)
Peki shell script neden shell script olarak çalışıyor? Kernel’ın format handler’larının, üzerinde açık bir etiket olmayan shell script’i güvenilir biçimde tanıması mümkün görünmüyor.
Çünkü bu davranış aslında kernel’ın işi değil. Bu, shell tarafında başarısız bir exec çağrısını ele almanın yaygın yolu.
Bir dosyayı shell üzerinden çalıştırdığında exec syscall’ı başarısız olursa, çoğu shell dosyayı yeniden denemek için bu kez bir shell process’i başlatır ve dosya adını ona ilk argüman olarak verir. Bash genelde kendi kendisini interpreter olarak kullanır; ZSH ise çoğu zaman sh‘in işaret ettiği şeyi, yani genellikle Bourne shell‘i çağırır.
Bu davranış o kadar yaygındır ki, Unix sistemleri arasında taşınabilirliği hedefleyen eski standartlardan biri olan POSIX‘te bile yer alır. POSIX bugün her araç ve sistem tarafından birebir takip edilmese de, pek çok davranış hâlâ onun izini taşır. Yine de hangi shell’in hangi interpreter’ı seçtiği ve binary olmayan dosyaya ne kadar tolerans gösterdiği implementation’a göre değişebilir.
Bir exec syscall’ı [ENOEXEC] ile eşdeğer bir hatayla başarısız olursa, kabuk komut adını ilk argüman olarak verdiği yeni bir kabuk süreci başlatır ve kalan argümanları da bu yeni kabuğa aktarır. Çalıştırılmak istenen dosya bir metin dosyası değilse kabuk bu denemeyi atlayabilir; bu durumda hata yazdırır ve 126 çıkış kodu döndürür.
Peki kullanıcı terminalde ./program yazdığında, bu execve çağrısını kim yapıyor? ls, cat, echo gibi komutlar neden doğrudan çalışıyor da ./benim-programim yazarken başına ./ koymamız gerekiyor? Bir sonraki bölümde, kullanıcı ile kernel arasındaki ilk elçi olan shell dünyasına dalacağız.