Bölüm 9: Bilgisayarındaki Çevirmen
CPU'ya“Sen”iKatmak yazısının parçası: bilgisayarının programları nasıl çalıştırdığına doğru inen uzun bir teknik tavşan deliği.
Şimdiye kadar bellekten söz ederken biraz eli gevşek davrandım. Örneğin ELF dosyaları verilerin yükleneceği belirli bellek adreslerini söylüyor; peki farklı process’lerde aynı adresleri kullanmaya çalışan yapılar neden çakışmıyor? Neden her process’in kendine ait ayrı bir bellek ortamı varmış gibi görünüyor?
Bir de buraya nasıl geldik? execve‘nin mevcut process’i yeni bir programla değiştiren bir syscall olduğunu artık biliyoruz, ama bu hâlâ birden fazla process’in nasıl ortaya çıktığını açıklamıyor. Daha da önemlisi, ilk programın nasıl başladığını hiç açıklamıyor. Diğer bütün yumurtaları yumurtlayan ilk tavuk hangi process?
Bu soruların cevabını Bölüm 11‘da bulacaksın:
forkile process klonlama, Copy-on-Write ve bilgisayarın açılışındainit process‘in nasıl doğduğunu orada ele alıyoruz. Şimdi önce bellek meselesini halledelim.
Yolculuğun sonuna yaklaşıyoruz. Bellek konusunu çözdükten sonra bilgisayarının açılıştan şu anda kullandığın yazılıma kadar nasıl geldiğine dair neredeyse tam bir resmimiz olacak.
Bu bölümde neyi çözüyoruz?
- RAM’in neden her process’e ayrı bir dünya gibi göründüğünü anlayacağız.
- Page table, MMU, TLB ve page fault kavramlarını aynı hikâyeye bağlayacağız.
- Bellek izolasyonu, ASLR, demand paging ve swap’ın hangi probleme çözüm olduğunu göreceğiz.
Bellek Aslında Sanal
Gelelim belleğe. Bunu önce adres defteri gibi düşün: Program “0x400000 adresindeki veriyi oku” dediğinde, bu adres çoğu zaman RAM çipindeki gerçek konum değildir. Process’in elinde kendine ait bir adres defteri vardır; MMU bu deftere bakıp “bu sanal adres fiziksel RAM’de şu sayfaya karşılık geliyor” çevirisini yapar.
CPU bir bellek adresinden okuma ya da o adrese yazma yaptığında, bunun aslında doğrudan physical memory‘deki (RAM’deki) o noktaya gitmediği ortaya çıkıyor. Bunun yerine, CPU önce virtual memory alanındaki bir konuma erişiyor.
CPU, memory management unit (MMU) denen bir birimle konuşur. MMU, sanal adresleri RAM’deki fiziksel adreslere çeviren bir sözlük gibi davranır. CPU’ya 0xfffaf54834067fe2 adresinden okuma yap denildiğinde, CPU önce MMU’ya gidip “bunu çevir” der. MMU eşleşen fiziksel adresin 0x53a4b64a90179fe2 olduğunu bulur ve bu sonucu CPU’ya verir. CPU da artık RAM’deki gerçek konuma erişebilir.

Bilgisayar ilk açıldığında bellek erişimleri doğrudan fiziksel RAM’e gider. Çok geçmeden işletim sistemi bu çeviri sözlüğünü kurar ve CPU’ya MMU üzerinden çalışmaya başlamasını söyler.
Her process’in sanal bellek alanı, farklı amaçlara hizmet eden bölgelere ayrılır. Aşağıdaki diyagram tipik bir process’in bellek düzenini gösteriyor: en altta text (program kodu) ve data (global/sabit değişkenler) segmentleri bulunur; yukarı doğru heap dinamik olarak büyür (malloc/mmap ile); en üstte ise stack yerel değişkenler ve fonksiyon çağrıları için kullanılır. Stack ve heap birbirine doğru büyür ama asla çakışmaz — aralarında geniş bir sanal adres boşluğu vardır. Kernel allocator, heap için mmap veya sbrk syscall’larını kullanarak sanal sayfaları fiziksel RAM’e eşler.
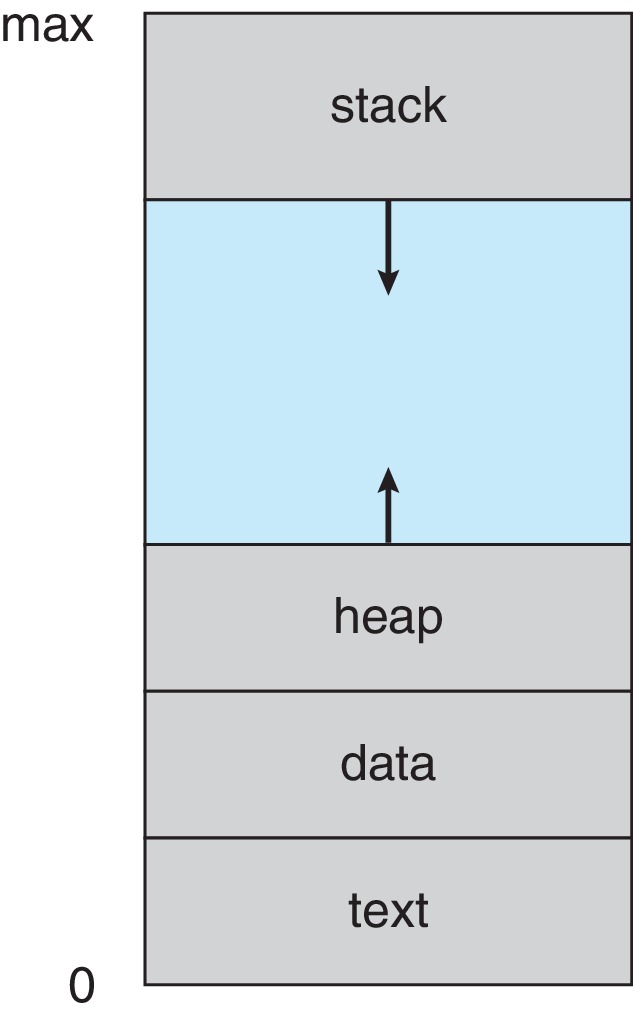
Kaynak: Silberschatz, Galvin, Gagne — Operating System Concepts, Ch. 3 — Processes, Slide 6.
Bu sözlüğe aslında page table denir; her bellek erişimini çeviren mekanizmanın adına da paging denir. Page table içindeki girdiler PTE (Page Table Entry — Sayfa Tablosu Girdisi) olarak adlandırılır ve her biri sanal bellek alanındaki belirli bir parçanın RAM’de nereye karşılık geldiğini söyler. Bu parçalar sabit boyuttadır ve boyut mimariye göre değişir. x86-64’ün varsayılan page boyutu 4 KiB’dir; yani her PTE, 4096 baytlık bir blok için eşleme tutar. Page = belleğin 4 KiB’lık bloğu; PTE = page table girdisi; Page Frame = fiziksel RAM’deki karşılık.
Başka bir deyişle, 4 KiB paging kullanıldığında bir adresin en düşük 12 biti MMU çevirisinden önce de sonra da aynı kalır. Bunun sebebi basit: 4096 baytlık bir page içindeki konumu göstermek için 12 bit gerekir.
x86-64 ayrıca işletim sistemlerinin 2 MiB veya 1 GiB gibi daha büyük page boyutlarını etkinleştirmesine de izin verir. Bu, adres çevirisini hızlandırabilir ama bellek parçalanmasını ve israfı artırabilir. Page ne kadar büyükse, adresin MMU tarafından çevrilmesi gereken kısmı o kadar küçülür.

Page table’ın kendisi de RAM’de tutulur. Milyonlarca girdi içerebilse bile her bir girdi yalnızca birkaç bayt civarında olduğundan, page table tek başına korkunç boyutlara ulaşmaz.
Boot sırasında paging’i etkinleştirmek için kernel önce RAM’de page table’ı kurar. Ardından page table’ın başlangıç adresini, page table base register (PTBR) denen register’a yazar. Son adımda da tüm bellek erişimlerinin MMU üzerinden çevrilmesi için paging’i etkinleştirir. x86-64’te bu yapı büyük ölçüde CR3 ve ilgili kontrol bitleri üzerinden yönetilir.
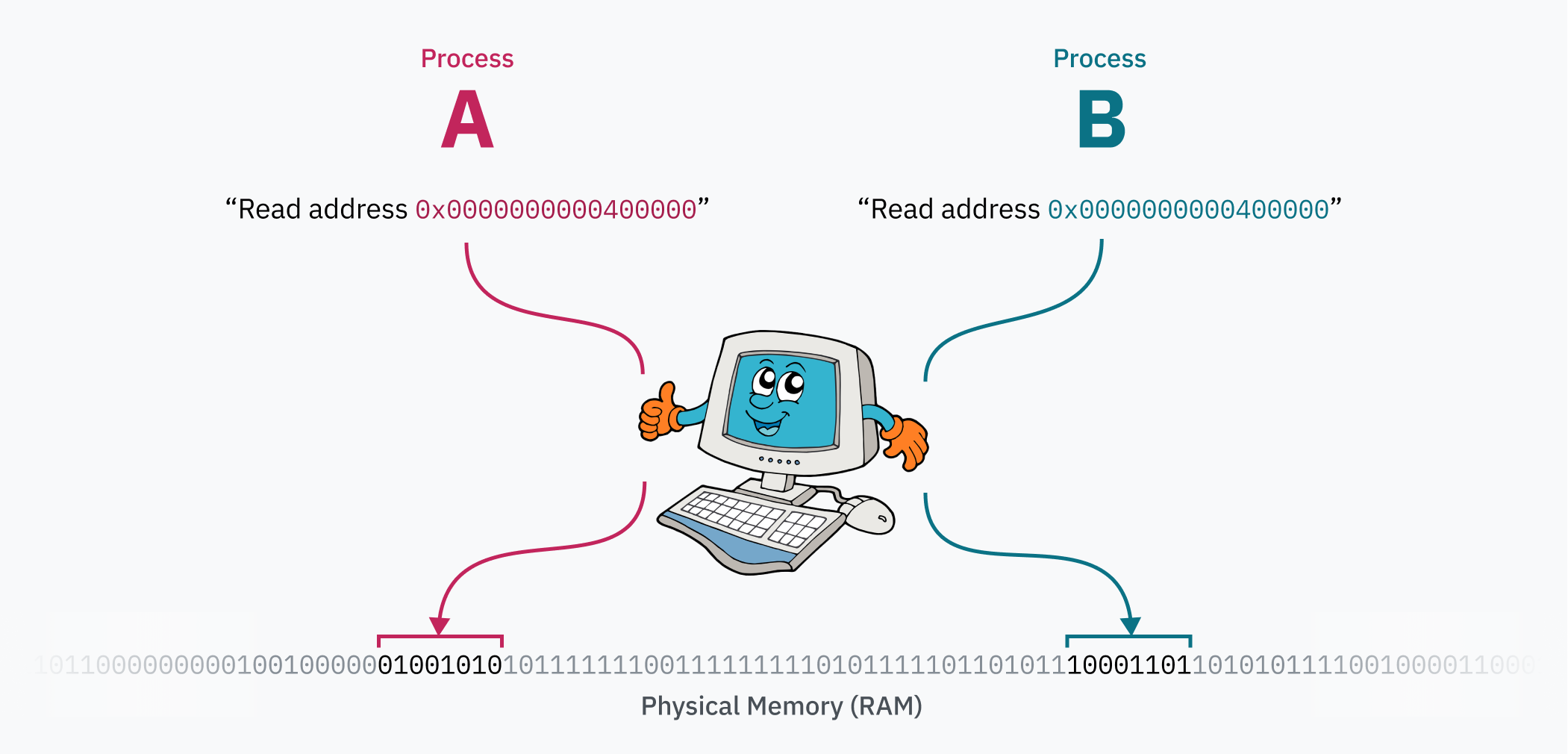
Paging’in asıl büyüsü, bilgisayar çalışırken page table’ın değiştirilebilmesidir. Her process’in izole bir bellek alanına sahip olması tam da böyle mümkün olur. İşletim sistemi context switch yaparken yaptığı kritik işlerden biri, sanal bellek alanını fiziksel bellekte başka bir yere yeniden eşlemektir. Diyelim iki process var: A process’inin kodu ve verileri 0x0000000000400000 adresinden erişiliyor olabilir; B process’i de kendi kodunu ve verisini aynı sanal adresten görüyor olabilir. Bu iki process aslında aynı adres aralığı için kavga etmez, çünkü bu sanal adresler fiziksel bellekte farklı yerlere çözülür. Kernel, process değişiminde bu eşlemeyi değiştirir.
Bir not: lanetli bir ELF gerçeği
Belirli koşullarda
binfmt_elf, belleğin ilk page’ini sıfırlarla eşlemek zorunda kalır. ELF’yi destekleyen ilk sistemlerden biri olan 1988 tarihli UNIX System V Release 4.0 (SVr4) için yazılmış bazı programlar, null pointer’ın okunabilir olmasına dayanır. Ve bir şekilde bazı programlar hâlâ bu davranışı bekliyor.Görünüşe göre bunu uygulayan Linux kernel geliştiricisi pek de mutlu değildi:
“Bunun nedenini soruyorsunuz??? Çünkü SVr4, page 0’ı salt okunur şekilde eşliyor ve bazı uygulamalar buna ‘bağımlı’. Bunları yeniden derleme şansımız olmadığı için SVr4 davranışını taklit ediyoruz. İç çek.”
Evet. İç çek.
Paging ile Güvenlik
Paging’in sağladığı process izolasyonu yalnızca kod ergonomisini iyileştirmez; aynı zamanda güçlü bir güvenlik katmanı oluşturur. Process’lerin birbirinin belleğine erişememesi, makalenin başındaki önemli sorulardan birini cevaplar:
Programlar doğrudan CPU üzerinde çalışıyorsa ve CPU doğrudan RAM’e erişebiliyorsa, neden başka process’lerin belleğine ya da aman kernel belleğine erişemiyorlar?
Bunu sanki haftalar önce sormuşuz gibi geliyor, değil mi?
Peki kernel belleği ne olacak? Öncelikle kernel’ın, çalışan tüm process’leri ve page table’ın kendisini takip etmek için kendi verilerine ihtiyacı var. Bir hardware interrupt, software interrupt ya da syscall tetiklendiğinde CPU kernel mode’a geçtiğinde, kernel kodunun bu belleğe erişebilmesi gerekir.
Linux’un yaklaşımı, sanal bellek alanının üst yarısını kalıcı olarak kernel’a ayırmaktır; bu yüzden Linux için higher-half kernel ifadesi kullanılır. Windows da benzer bir yaklaşım izler. macOS tarafı ise… biraz daha karmaşık ve okurken beynimin kulaklarımdan akmasına neden oldu.

User-space process’lerin kernel belleğini okuyabilmesi ya da yazabilmesi çok kötü olurdu; bu yüzden paging ikinci bir güvenlik katmanı daha sağlar: her page için izin bayrakları tutulur. Bir bayrak, page’in yazılabilir mi yoksa yalnızca okunabilir mi olduğunu söyler. Başka bir bayrak ise bu page’e yalnızca kernel mode’dan erişilebileceğini belirtir. Kernel space’in tamamı, işte bu izinler sayesinde user-space programları için fiilen erişilemez hâle gelir. Teknik olarak bazı sistemlerde eşleme vardır, ama izin yoktur. NX (No-eXecute) biti, belirli bellek sayfalarında kod çalıştırılmasını engeller — W^X (write XOR execute) güvenlik politikasının temelidir.
Derinleşme: Meltdown sonrası KPTI
Eskiden performans için kernel adreslerinin user process page table’larında görünmesi yaygındı; izin bitleri user mode erişimini engelliyordu. Meltdown gibi donanım açıklarından sonra Linux tarafında KPTI/PTI gibi tekniklerle user ve kernel page table’ları daha sert ayrılabildi. Ana fikir değişmiyor: user programı kernel belleğini normal yollarla okuyamaz; sadece implementasyon ayrıntısı ve performans maliyeti değişiyor.

Bellek güvenliğinin bir diğer temel taşı da ASLR‘dir (Address Space Layout Randomization). Stack, heap ve kütüphanelerin başlangıç adresleri her çalıştırmada rastgele kaydırılır; böylece bir saldırganın bellekteki belirli adresleri tahmin etmesi zorlaşır.
Page table’ın kendisi de aslında kernel belleğinde durur. Timer chip bir hardware interrupt tetikleyip context switch başlattığında, CPU ayrıcalık seviyesini kernel mode’a çıkarır ve Linux kernel koduna atlar. Kernel mode’da olduğu için CPU artık korumalı kernel bellek bölgesine erişebilir. Kernel, page table’ı güncelleyip sanal belleğin alt yarısını yeni process için yeniden eşler. User mode’a geri dönüldüğünde bu erişim tekrar kapanır.
Kısacası, neredeyse her bellek erişimi MMU’dan geçer. Interrupt descriptor table içindeki handler adresleri bile aslında kernel’ın sanal adres alanına işaret eder.
Hierarchical Paging ve Diğer Optimizasyonlar
64-bit sistemlerde bellek adresleri 64 bit uzunluğunda olabilir; bu da teorik sanal adres alanının devasa bir 16 exbibyte olabileceği anlamına gelir. Bu sayı, PiB ölçekli büyük makinelerin bile çok ötesindedir. Yani sorun “gerçek makinelerde bu kadar RAM var mı?” değil; CPU ve işletim sisteminin böylesine büyük bir adres uzayını pratik ve verimli biçimde nasıl temsil edeceğidir.
Sanal adres alanındaki her 4 KiB blok için page table’da ayrı bir girdi gerektiğini düşün. Bu durumda 4.503.599.627.370.496 page table girdisine ihtiyacın olurdu. Her girdi 8 bayt ise, sadece page table’ı saklamak için 32 pebibyte RAM gerekirdi. Evet, bu sayı gerçek makinelerdeki toplam RAM miktarından bile absürt derecede büyük.
Bir not: neden bu kadar tuhaf birimler kullanıyorum?
Bunun nadir ve biraz çirkin göründüğünü biliyorum, ama ikili tabanlı bayt boyutlarıyla (2’nin kuvvetleri) onluk SI birimlerini ayırmanın önemli olduğunu düşünüyorum. Bir kilobyte, yani kB, 1000 bayttır. Bir kibibyte, yani KiB, 1024 bayttır. CPU’lar ve bellek adresleri bağlamında sayılar çoğu zaman 2’nin kuvvetleriyle ilerlediği için bu ayrım bana anlamlı geliyor.
Sanal bellek alanının tamamı için düz bir page table tutmak imkânsız, ya da en azından korkunç derecede verimsiz olacağı için, CPU mimarileri hierarchical paging kullanır. Bu modelde, tek bir dev tablo yerine farklı ayrıntı seviyelerinde birden çok page table katmanı bulunur. Üst katmanlar büyük bellek bloklarını kapsar ve daha küçük aralıklar için alt tablolara işaret eder. 4 KiB page’lere karşılık gelen tek tek girdiler ağacın yapraklarıdır.
x86-64 tarihsel olarak 4 seviyeli hierarchical paging kullandı. Bu düzende, her page table girişi adresin bir kısmıyla indekslenir. En üst anlamlı bitler bir önek gibi davranır; böylece o girdi bu bitlerle başlayan tüm adres aralığını temsil eder. Sonra sıradaki bit kümesi alt tablonun içinde bir sonraki adımı belirler ve bu böyle devam eder.
x86-64’ün 4 seviyeli paging tasarımında sanal işaretçilerin sadece 48 biti çeviri için kullanılır. Ancak üstteki 16 bit donanım tarafından göz ardı edilmez; Canonical Addressing kuralı gereği bu bitler 47. bitin kopyası olmak zorundadır. Eğer 47. bit 0 ise üst 16 bit tamamen 0 olmalıdır; 1 ise tamamen 1 olmalıdır. Bu, toplam 256 TiB canonical sanal adres alanı demektir; pratik anlatıda düşük yarı ve yüksek yarı kabaca 128 TiB + 128 TiB gibi düşünülebilir. (Tam 64 bit kullansan sayı 16 EiB olurdu ki, gereksiz derecede büyüktür.)
İlk 16 bitin atlanması şu anlama gelir: page table’ın ilk seviyesini indeksleyen “en yüksek anlamlı bitler” aslında 63. bitten değil, 47. bitten başlar. Bu yüzden bu bölümün başındaki higher-half kernel diyagramı teknik olarak biraz yalındır; orta nokta, tam 64-bit uzayın değil, fiilen kullanılan daha dar adres uzayının orta noktası üzerinden düşünülmelidir.
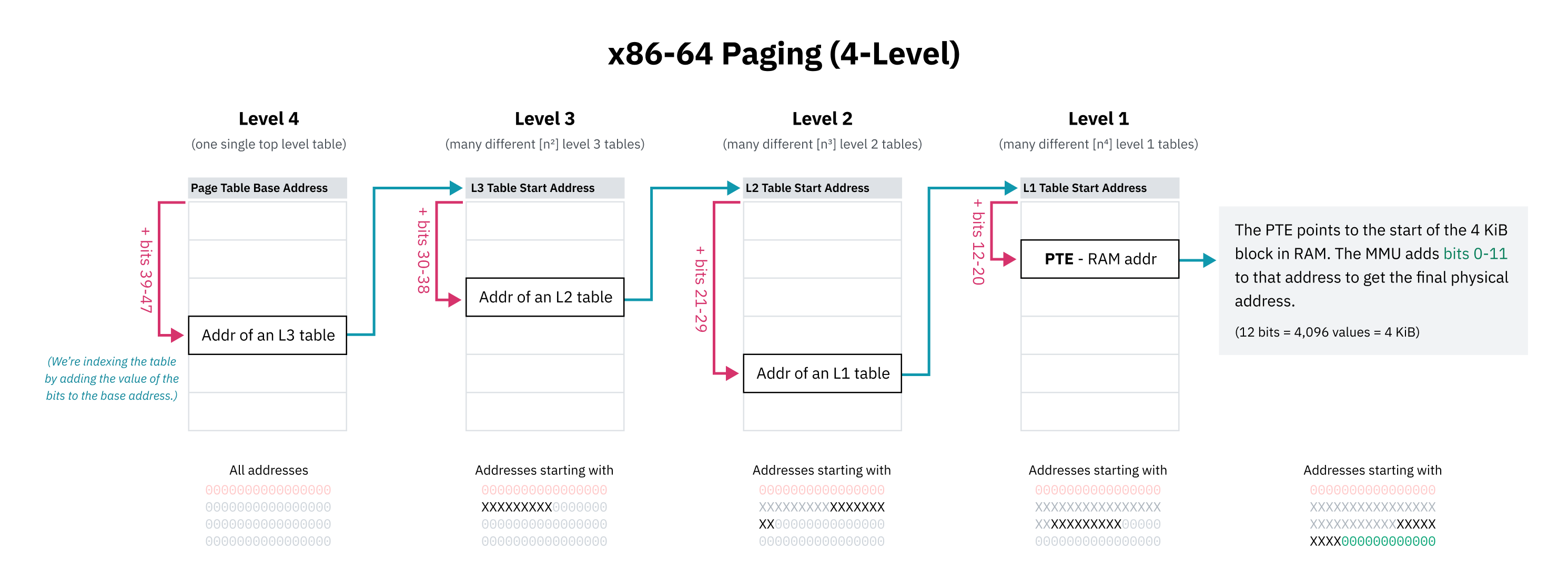
Hierarchical paging alan sorununu çözer; çünkü ağacın herhangi bir seviyesinde, bir sonraki tabloya işaret eden pointer boş (0x0) olabilir. Bu sayede page table’ın tüm alt ağaçları atlanabilir; yani eşlenmemiş sanal adres alanı RAM’de yer kaplamaz. CPU, ağacın üst seviyelerinde boş bir giriş gördüğünde erişimi hızlıca başarısız sayabilir. Page table girdilerinde ayrıca “adres geçerli görünse bile kullanılamaz” demeye yarayan bayraklar da vardır.
Bir başka avantaj da, büyük sanal adres bölgelerini topluca değiştirebilmektir. Kernel, bir process için bir fiziksel bellek alanını, başka bir process içinse başka bir alanı hazır tutabilir. Process değiştirirken ağacın en üst düzeyindeki birkaç pointer’ı güncellemek yeterli olur. Eğer tüm eşleme düz bir dizi şeklinde saklansaydı, kernel’ın çok daha fazla girdiyi güncellemesi gerekirdi.
Biraz önce x86-64’ün “tarihsel olarak” 4 seviyeli paging kullandığını söyledim, çünkü yeni işlemciler 5 seviyeli paging destekliyor. Mimari açıdan 5 seviye, linear/canonical adres tarafını 57 bit’e kadar genişleterek toplam 128 PiB sanal alana ulaşmayı sağlar. Linux kullanıcı alanı açısından bunun pratik karşılığı 56-bit user virtual address penceresidir; ancak uyumluluk için 47-bit üstüne yerleşim varsayılan olarak her zaman otomatik yapılmayabilir. Program çok yüksek bir adres için açıkça hint verirse kernel bu geniş alandan yararlanabilir.
Bir not: fiziksel adres alanı sınırları
Tıpkı işletim sistemlerinin sanal adresler için tüm 64 biti kullanmaması gibi, CPU’lar da fiziksel adresler için tam 64 biti kullanmaz. 4 seviyeli paging döneminde x86-64 CPU’lar genelde 46 bitten fazlasını kullanmıyordu; bu da fiziksel adres alanını 64 TiB ile sınırlıyordu. 5 seviyeli paging ile bu destek 52 bite çıktı ve 4 PiB fiziksel adres alanı mümkün hâle geldi.
İşletim sistemi perspektifinden bakarsan, sanal adres alanının fiziksel adres alanından daha büyük olması avantajlıdır. Linus Torvalds’ın dediği gibi, en az iki kat büyük olması gerekir; on kat büyük olması ise daha da iyidir.
TLB: MMU’nun Önbelleği
TLB olmasaydı her bellek erişiminde 4 seviyeli page table’ı baştan sona gezmek, bellek gecikmesini 4-5 kat artırır. Bu yüzden MMU’nun içinde TLB (Translation Lookaside Buffer) adı verilen küçük ama ultra hızlı bir önbellek bulunur.
TLB, son kullanılan sanal → fiziksel adres çevirilerini saklar. Bir bellek erişimi yapıldığında MMU önce TLB’ye bakar:
- TLB hit: Çeviri önbellekte varsa → anında fiziksel adrese ulaşılır.
- TLB miss: Çeviri yok → MMU page table walk yapar, sonucu TLB’ye ekler ve yoluna devam eder.
TLB, modern CPU performansının olmazsa olmaz bir parçasıdır. Tasarımı mimariye göre değişir; bazı TLB’ler fully associative, bazıları set-associative olabilir. Ortak fikir aynıdır: küçük, çok hızlı ve adres çevirisi yoluna özel bir önbellek kullanarak her erişimde pahalı page table walk yapmayı önlemek.
TLB’nin ilginç bir yan etkisi de şudur: context switch sırasında TLB’nin temizlenmesi (flush) gerekir, çünkü farklı process’lerin page table’ları tamamen farklıdır. Bu flush işlemi, context switch’in gizli maliyetlerinden biridir. Modern CPU’lar bunu hafifletmek için ASID (Address Space ID) veya PCID (Process Context ID) gibi mekanizmalar kullanır — her TLB girişi bir process kimliğiyle etiketlenebilir, böylece her context switch’te tam TLB flush yapmak gerekmeyebilir.
Huge Pages kullanmanın asıl büyük avantajı da TLB verimliliğidir; tek bir TLB girdisi ile 4 KiB yerine 2 MiB’lık (veya 1 GiB’lık) bir alanı adresleyebilirsiniz. Bu, TLB miss oranlarını dramatik şekilde düşürür.
Swapping ve Demand Paging
Bellek erişimi birkaç sebeple başarısız olabilir: adres geçersiz olabilir, page table’da hiç eşlenmemiş olabilir ya da girdi mevcut değil olarak işaretlenmiş olabilir. Bu durumların herhangi birinde MMU, sorunu kernel’ın ele alabilmesi için page fault adlı bir donanım exception/trap’i üretir.
Bazı durumlarda erişim gerçekten geçersizdir ya da yasaktır. Böyle olduğunda kernel büyük ihtimalle programı segmentation fault ile sonlandırır.
$ ./program
Segmentation fault (core dumped)
$Bir not: segfault ontolojisi
“Segmentation fault” farklı bağlamlarda biraz farklı şeyler ifade eder. MMU, yetkisiz bellek erişiminde donanım seviyesinde bir hata üretir; aynı ad, işletim sisteminin bu tür geçersiz erişimler yüzünden programlara gönderdiği sinyal için de kullanılır.
Başka durumlarda ise bellek erişiminin bilerek başarısız olmasına izin verilir; böylece işletim sistemi eksik veriyi yükleyip sonra kontrolü CPU’ya geri verebilir. Örneğin işletim sistemi bir dosyayı, içeriğini daha RAM’e taşımadan sanal belleğe eşleyebilir. Adrese gerçekten erişildiğinde page fault oluşur; kernel da ilgili veriyi diskten RAM’e yükler. Buna demand paging denir.

Bu mekanizma sayesinde mmap gibi syscall’lar tüm dosyaları tembel biçimde sanal belleğe eşleyebilir. Eğer LLaMa.cpp’yi tanıyorsan, Justine Tunney kısa süre önce yükleme mantığını mmap temelli hâle getirerek bunu ciddi biçimde optimize etti. Eğer bilmiyorsan, işlerine bir göz at; Cosmopolitan Libc ve APE epey ilginç.
Bu değişiklik etrafında internette bol miktarda tartışma, daha fazla tartışma ve biraz daha tartışma var. Rastgele internet insanları bana bağırmasın diye bunu not düşüyorum. O dramaların tamamını okumadım ama Justine’in yaptığı işlerin ilginç olduğu fikrim değişmedi.
Bir programı ve kütüphanelerini çalıştırdığında kernel aslında her şeyi baştan RAM’e kopyalamaz. Çoğu durumda yaptığı şey, dosya için bir mmap oluşturmak olur; CPU kodu gerçekten yürütmeye çalıştığında page fault oluşur ve kernel o page’i fiziksel bellekle doldurur.
Demand paging, muhtemelen “swap” ya da “paging” adıyla duyduğun başka bir tekniği de mümkün kılar. İşletim sistemi bellek page’lerini diske yazıp sonra fiziksel RAM’den çıkarabilir; ama bunların sanal adreslerini page table’da tutmaya devam eder. Sonra aynı veri tekrar istenirse, diskten geri yükleyip erişimi yeniden mümkün kılar. Gerekirse diskten gelen sayfaya yer açmak için RAM’deki başka bir page’i swap out etmek zorunda kalabilir. Disk I/O yavaş olduğu için işletim sistemleri iyi page replacement algoritmaları ile bunu mümkün olduğunca az yapmaya çalışır.
Düşünmesi eğlenceli bir hack de şudur: page table içindeki fiziksel adres alanlarını, dosyaların diskteki konumlarını saklamak için kullanabilirsin. MMU zaten “present” biti kapalı bir girdi gördüğünde page fault üreteceği için, o alanların gerçek RAM adresi olmaması bazı tasarımlarda sorun yaratmaz. Her yerde pratik değildir ama akılda tutması keyiflidir.
Peki process izolasyonu, yetki sınırları ve kernel’ın kaynak yönetimi modern bulut sistemlerinde nasıl paketleniyor? Bir sonraki bölümde kısa bir modern uygulama molası verip Docker ve Kubernetes’in arkasındaki container fikrini keşfedeceğiz. Container’lar sanal bellekten tek başına ibaret değildir; namespace, cgroup, seccomp ve capabilities gibi Linux mekanizmalarının birlikte kullanılmasına dayanır.
10. bölüme devam et: Container ve İzolasyon