Bilgisayarlarla pek çok şey yaptım, ama bilgimde hep bir boşluk vardı: Bilgisayarında bir program çalıştırdığında tam olarak ne oluyor? Bu soruya takılıp kalıyordum; gerekli low-level bilginin büyük kısmına sahiptim ama parçaları bir araya getirmekte zorlanıyordum. Programlar gerçekten doğrudan CPU üzerinde mi çalışıyor, yoksa arada başka şeyler mi oluyor? Syscall’ları kullanıyordum ama bunlar nasıl çalışıyordu? Aslında neydiler? Birden fazla program aynı anda nasıl çalışabiliyordu?
Sonunda dayanamadım ve olabildiğince çok şeyi çözmeye koyuldum. Üniversiteye gitmiyorsan bu konuda derli toplu sistem kaynağı pek yok; bu yüzden kalite seviyesi değişen, bazen de birbiriyle çelişen tonla kaynağı taramak zorunda kaldım. Birkaç haftalık araştırma ve neredeyse 40 sayfalık nottan sonra, bilgisayarların açılıştan program yürütmeye kadar nasıl çalıştığına dair çok daha sağlam bir zihinsel modele sahip olduğumu düşünüyorum. Ben bunları öğrenirken elimde böyle bir yazı olmasını çok isterdim, o yüzden keşke biri benim için yazsaydı dediğim makaleyi şimdi ben yazıyorum.
Bir şeyi ancak başka birine açıklayabildiğinde gerçekten anladığını söylerler ya, biraz da o hesap.
Acelen mi var? Zaten bunları bildiğini mi sanıyorsun?
3. bölüme geç; Linus Torvalds’ın kendisi değilsen muhtemelen yeni bir şey öğreneceksin.
Bölüm 1: Temeller
Bu makaleyi yazarken beni tekrar tekrar şaşırtan şey, bilgisayarların ne kadar basit olduğuydu. Gerçekte olduğundan daha karmaşık ya da daha soyut bir yapı beklememek benim için hâlâ kolay değil. Devam etmeden önce aklına kazımanı istediğim tek bir şey varsa o da şu: basit görünen birçok şey gerçekten de basittir. Bu sadelik hem çok güzel hem de zaman zaman epey lanetlidir.
Bilgisayarının özünde nasıl çalıştığına dair temel resimle başlayalım.
Bilgisayarlar Nasıl Tasarlanır?
Bir bilgisayarın merkezi işlem birimi (CPU), bütün hesaplamalardan sorumludur. İşin patronu odur. Makine açıldığı anda çalışmaya başlar ve talimat üstüne talimat yürüterek durmadan devam eder.
İlk seri üretim CPU, 1960’ların sonunda İtalyan fizikçi ve mühendis Federico Faggin tarafından tasarlanan Intel 4004‘tü. Bugün kullandığımız 64-bit sistemler yerine 4-bit bir mimariye sahipti ve modern işlemcilerden çok daha az karmaşıktı, ama temel çalışma mantığının büyük kısmı bugün hâlâ aynı.
CPU’nun yürüttüğü “talimatlar” sadece ikili veridir: önce hangi talimatın çalıştırıldığını belirten bir ya da birkaç baytlık opcode gelir, ardından o talimatın ihtiyaç duyduğu veri yer alır. Makine kodu dediğimiz şey, aslında bu ikili talimatların art arda dizilmesinden ibarettir. Assembly, insanların ham bitlere göre çok daha rahat okuyup yazabildiği bir gösterimdir; ama sonuçta her zaman CPU’nun anlayacağı ikili biçime derlenir.
Bir not: Talimatlar makine kodunda her zaman yukarıdaki örnekteki gibi 1:1 görünmez. Örneğin add eax, 512, 05 00 02 00 00 şeklinde kodlanır.
İlk bayt (05), özellikle EAX register’ına 32-bit bir sayı ekleme işlemini ifade eden opcode’dur. Kalan baytlar ise little-endian sıra ile yazılmış 512 (0x200) değeridir.
Defuse Security, assembly ile makine kodu arasındaki çeviriyle oynamak için yararlı bir araç hazırlamış.
RAM, bilgisayarının ana belleğidir; çalışan programların kullandığı tüm verilerin tutulduğu büyük ve genel amaçlı alan budur. Buna program kodunun kendisi de, işletim sisteminin kernel kodu da dahildir. CPU makine kodunu doğrudan RAM’den okur; RAM’e yüklenmemiş bir kod çalıştırılamaz.
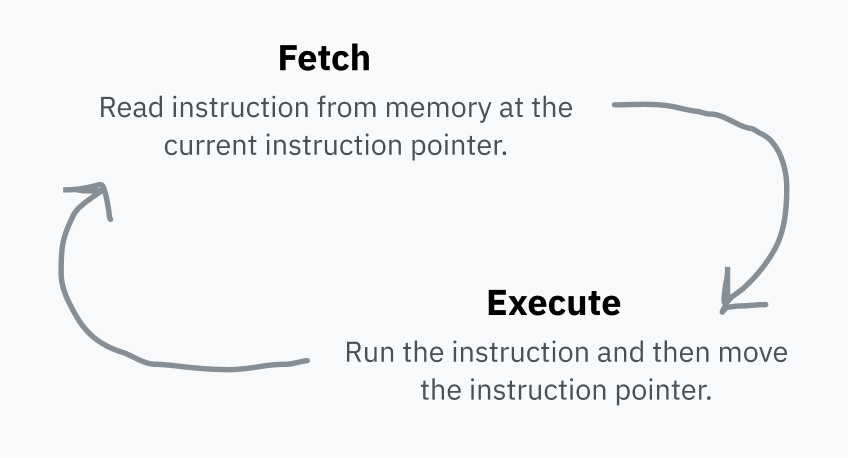
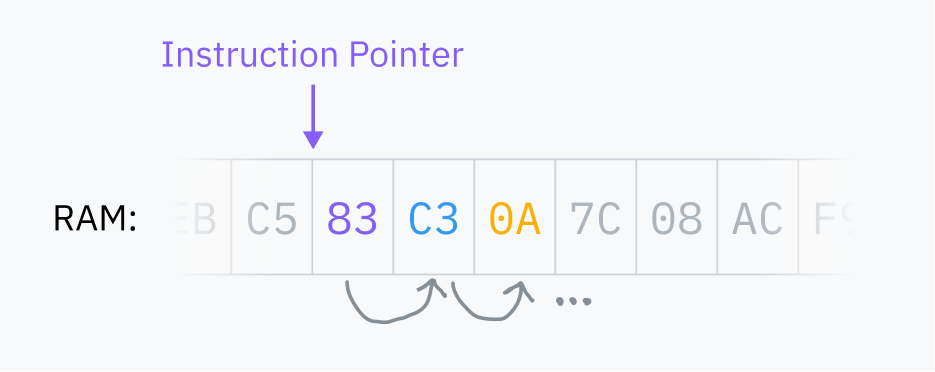
CPU, RAM’de sıradaki talimatın nerede olduğunu gösteren bir instruction pointer tutar. Her talimat çalıştırıldıktan sonra bu göstericiyi ilerletir ve aynı şeyi tekrar yapar. Buna fetch-execute cycle denir.
Bir talimat yürütüldükten sonra instruction pointer, RAM’de o talimatın hemen sonrasına ilerler; böylece sıradaki talimatı işaret eder. Kodun çalışması dediğimiz şey tam olarak budur. Talimatlar bellekte hangi sıradaysa CPU onları o sırayla yürütür. Bazı talimatlar ise instruction pointer’a başka bir adrese atlamasını söyler; böylece dallanma, koşullu mantık ve tekrar kullanılabilir kod mümkün olur.
Bu instruction pointer bir register içinde tutulur. Register’lar, CPU’nun çok hızlı okuyup yazabildiği küçük depolama alanlarıdır. Her CPU mimarisinin, geçici değer tutmaktan işlemci yapılandırmasına kadar farklı işler için kullandığı sabit bir register kümesi vardır.
Önceki diyagramdaki ebx gibi bazı register’lara makine kodundan doğrudan erişilebilir.
Bazı register’lar ise CPU tarafından daha içsel amaçlarla kullanılır; yine de çoğu zaman özel talimatlarla okunabilir veya güncellenebilirler. Instruction pointer buna iyi bir örnektir: doğrudan okunmaz ama örneğin bir jump talimatı ile değiştirilebilir.
İşlemciler Naiftir
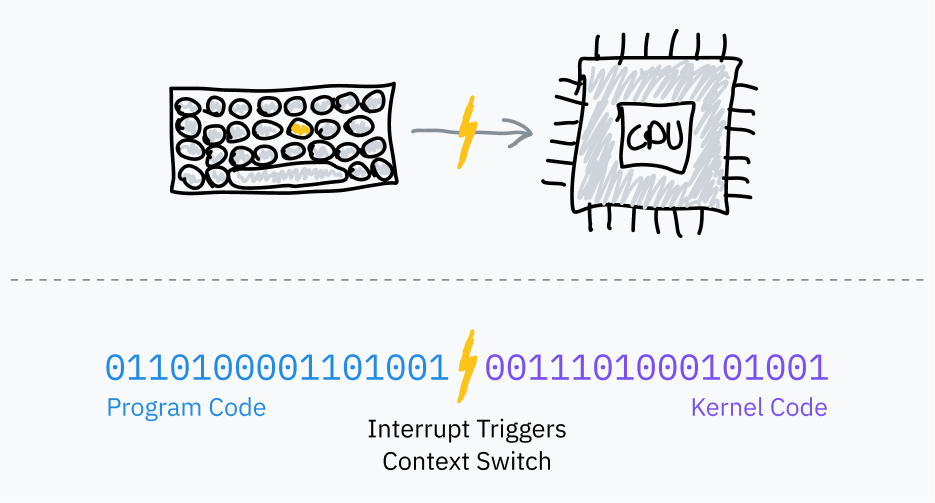
Asıl soruya dönelim: Bilgisayarında çalıştırılabilir bir programı başlattığında ne oluyor? Önce onu çalıştırmaya hazırlamak için bir sürü kurulum yapılır, bunların hepsini birazdan göreceğiz, ama sonunda dosyanın içindeki makine kodu RAM’e yerleştirilir. Ardından işletim sistemi CPU’ya instruction pointer’ı o konuma ayarlamasını söyler. CPU da fetch-execute cycle’ı normal şekilde sürdürür ve program çalışmaya başlar.
(Bu, benim için gerçekten afallatıcı anlardan biriydi. Bu makaleyi okumak için kullandığın program da tam olarak bu şekilde çalışıyor. CPU’n şu anda tarayıcının talimatlarını RAM’den sırayla okuyup yürütüyor.)
CPU’ların dünya görüşü aslında inanılmaz derecede dardır: yalnızca o andaki instruction pointer’ı ve biraz da iç durumu görürler. Process dediğimiz şey tamamen işletim sistemi soyutlamasıdır; CPU’nun doğal olarak bildiği ya da takip ettiği bir kavram değildir.
*ellerini sallayarak* process’ler, OS geliştiricileri büyük bayt lobisi tarafından daha fazla bilgisayar satmak için uydurulmuş soyutlamalardır
Benim için bu, cevap verdiğinden çok daha fazla soru doğurdu:
CPU çoklu işlemeyi bilmiyorsa ve sadece talimatları sırayla yürütüyorsa, neden tek bir programın içinde sıkışıp kalmıyor? Birden fazla program aynı anda nasıl çalışabiliyor?
Programlar doğrudan CPU üzerinde çalışıyorsa ve CPU doğrudan RAM’e erişebiliyorsa, neden başka process’lerin belleğine ya da Allah korusun kernel belleğine erişemiyorlar?
Madem konu açıldı: Her process’in istediği talimatı çalıştırıp bilgisayarına istediğini yapmasını engelleyen şey ne? Ve syscall denen şey tam olarak nedir?
Bellek meselesi kendi bölümünü hak ediyor; onu Bölüm 5‘te ele alacağız. Kısa versiyon şu: bellek erişimlerinin çoğu, tüm adres uzayını yeniden eşleyen bir yönlendirme katmanından geçer. Şimdilik, programların tüm RAM’e doğrudan erişebildiğini ve bilgisayarın aynı anda sadece tek bir process çalıştırabildiğini varsayalım. Bu varsayımların ikisini de birazdan bozacağız.
İlk tavşan deliğimize, yani syscall’lar ve güvenlik halkaları dünyasına atlama zamanı.
Bu arada kernel nedir?
Bilgisayarındaki macOS, Windows ya da Linux gibi işletim sistemi, temel işlerin yürümesini sağlayan bütün yazılım katmanıdır. “Temel işler” çok muğlak bir ifade ve “işletim sistemi” terimi de kime sorduğuna göre değişir; kimi insanlar buna varsayılan uygulamaları, font’ları ve ikonları da katar.
Ama kernel, işletim sisteminin çekirdeğidir. Bilgisayar açıldığında instruction pointer bir yerdeki programa atlar; işte o program kernel’dır. Kernel, belleğe, çevre birimlerine ve sistem kaynaklarına neredeyse tam erişime sahiptir ve kullanıcı alanı programlarını çalıştırmaktan sorumludur. Bu makale boyunca kernel’ın bu erişime nasıl sahip olduğunu ve kullanıcı alanı programlarının neden sahip olmadığını göreceğiz.
Linux tek başına bir kernel’dır; kullanılabilir bir sistem olması için shell’ler, görüntü sunucuları ve başka birçok user-space yazılımına ihtiyaç duyar. macOS’un kernel’ının adı XNU‘dur ve Unix benzeridir; modern Windows kernel’ı ise NT Kernel olarak bilinir.
Hepsine Hükmedecek İki Halka
Bir işlemcinin bulunduğu mode (ayrıcalık seviyesi ya da ring olarak da geçer), neleri yapabildiğini belirler. Modern mimarilerde en az iki temel seçenek vardır: kernel/supervisor mode ve user mode. İkiden fazla mode desteklenebilir, ama pratikte bugün çoğunlukla bu ikisi kullanılır.
Kernel mode’da neredeyse her şey serbesttir: CPU desteklediği her talimatı çalıştırabilir ve her belleğe erişebilir. User mode’da ise yalnızca belirli talimatlara izin verilir, G/Ç ve bellek erişimi kısıtlanır ve birçok CPU ayarı kilitlenir. Genel olarak kernel ve sürücüler kernel mode’da, uygulamalar ise user mode’da çalışır.
İşlemciler açılışta kernel mode’da başlar. Bir programı çalıştırmadan önce kernel, user mode’a geçiş yapar.
Gerçek bir mimaride bunun nasıl göründüğüne örnek: x86-64’te mevcut ayrıcalık seviyesi (CPL), cs adlı code segment register’ından okunabilir. Özellikle CPL, cs register’ının en düşük anlamlı iki bitinde tutulur. Bu iki bit, x86-64’ün dört olası ring’ini temsil eder: ring 0 kernel mode’dur, ring 3 ise user mode’dur. Ring 1 ve 2 sürücüler için düşünülmüştür ama bugün yalnızca birkaç eski ve niş işletim sistemi tarafından kullanılır. Örneğin CPL bitleri 11 ise CPU ring 3, yani user mode’dadır.
Syscall Tam Olarak Nedir?
Programlar user mode’da çalışır çünkü bilgisayara tam erişim konusunda onlara güvenilmez. User mode, sistemin büyük kısmına erişimi engeller; ama programların yine de G/Ç yapması, bellek ayırması ve bir şekilde işletim sistemiyle konuşması gerekir. Bunun için user mode’da çalışan yazılımın kernel’dan yardım istemesi gerekir. Kernel da bu sırada kendi güvenlik kontrollerini uygulayabilir.
İşletim sistemiyle etkileşen kod yazdıysan muhtemelen open, read, fork ve exit gibi fonksiyonları görmüşsündür. Bu fonksiyonların altında, işletim sisteminden yardım istemek için syscall‘lar kullanılır. Syscall, bir programın user space’ten kernel space’e geçiş başlatmasına; yani program kodundan işletim sistemi koduna atlamasına izin veren özel prosedürdür.
User space’ten kernel space’e kontrol devri, software interrupt denilen işlemci özelliğiyle yapılır:
Boot sırasında işletim sistemi, RAM’de interrupt vector table (IVT; x86-64 tarafında interrupt descriptor table olarak geçer) adı verilen bir tablo kurar ve CPU’ya kaydeder. IVT, interrupt numaralarını handler kodu işaretçileriyle eşler.
Ardından user-space programları, INT gibi bir talimat kullanarak CPU’ya şu işi yaptırabilir: IVT’de ilgili interrupt numarasını bul, kernel mode’a geç ve instruction pointer’ı oradaki handler adresine atla.
Bu kernel kodu işi bitirdiğinde, IRET gibi bir talimatla CPU’ya user mode’a geri dönmesini ve instruction pointer’ı interrupt’ın tetiklendiği yere geri koymasını söyler.
User-mode programları I/O’ya ya da belleğe doğrudan erişemez. Dış dünyayla etkileşime geçmek için işletim sisteminden yardım istemeleri gerekir.
Programlar, INT ve IRET gibi özel makine kodu talimatlarıyla kontrolü işletim sistemine devredebilir.
Programlar ayrıcalık seviyesini doğrudan değiştiremez. Software interrupt’lar güvenlidir çünkü CPU, işletim sistemi kodunda nereye atlanacağını önceden kernel tarafından yapılandırılmış bir tablodan alır. Interrupt vector table yalnızca kernel mode’da değiştirilebilir.
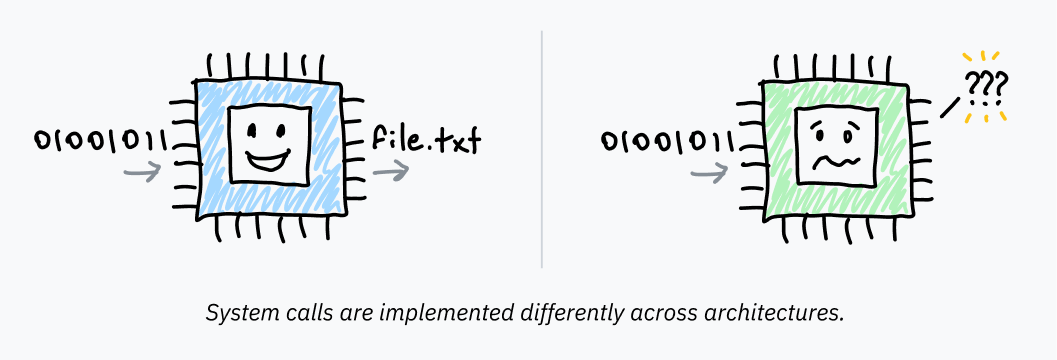
Bir program syscall tetiklerken kernel’a veri de aktarmalıdır. Kernel’ın hangi syscall’ın çağrıldığını ve örneğin hangi dosya adının açılacağını bilmesi gerekir. Bunun nasıl aktarıldığı mimariye ve işletim sistemine göre değişir; genellikle interrupt tetiklenmeden önce belirli register’lara ya da stack’e veri yazılır.
Mimariler arasında syscall çağırma biçimlerinin değişmesi, programcıların her program için bunu elle uygulamasını pratik olmaktan çıkarır. Aynı zamanda işletim sistemlerinin de “eski biçimi kullanan her program bozulur” korkusuyla bu detayları sabitlemesini zorlaştırır. Üstelik artık ham assembly ile program yazmıyoruz; bir dosya okumak isteyen herkesin assembly yazması beklenemez.
Bu yüzden işletim sistemleri, bu interrupt mekanizmasının üstüne bir soyutlama katmanı koyar. Gerekli assembly talimatlarını saran yeniden kullanılabilir üst seviye kütüphane fonksiyonları Unix benzeri sistemlerde libc, Windows’ta ise ntdll.dll tarafından sağlanır. Bu kütüphane fonksiyonlarına yaptığın çağrı doğrudan kernel mode’a geçmez; bunlar normal fonksiyon çağrılarıdır. Kütüphanenin içinde bir yerde assembly devreye girer ve kontrol gerçekten kernel’a aktarılır.
Unix benzeri bir sistemde C içinden exit(1) çağırdığında, bu fonksiyon önce syscall numarasını ve argümanlarını doğru register’lara ya da stack’e yerleştirir, sonra da interrupt ya da mimariye özgü syscall talimatını tetikler. Bilgisayarlar gerçekten çok havalı.
Hız İhtiyacı / Biraz CISC Olalım
x86-64 gibi birçok CISC mimarisi, syscall’ların ne kadar yaygın kullanıldığını görünce bu iş için özel talimatlar ekledi.
Intel ve AMD, x86-64 tarafında bu konuda tam uyum sağlayamadı; sonuçta iki ayrı optimize syscall talimatı ortaya çıktı. SYSCALL ve SYSENTER, INT 0x80 gibi yöntemlere göre optimize edilmiş alternatiflerdir. Bunların dönüş tarafında ise SYSRET ve SYSEXIT bulunur; bunlar user space’e hızlı dönmek için tasarlanmıştır.
(AMD ve Intel işlemciler bu talimatlar konusunda birebir aynı davranmaz. SYSCALL genellikle 64-bit programlar için daha iyi tercih olurken, SYSENTER 32-bit programlarda daha iyi destek görür.)
Buna karşılık RISC mimarileri genelde böyle özel talimatlar eklemeye daha az meyillidir. Apple Silicon’un dayandığı AArch64 mimarisi, hem syscall’lar hem de software interrupt’lar için yalnızca tek bir interrupt talimatı kullanır. Mac kullanıcıları bu konuda fena durumda değil :)
Vay be, bu çok şeydi. Kısa bir özet geçelim:
İşlemciler talimatları sonsuz bir fetch-execute cycle içinde yürütür ve doğal olarak ne işletim sistemi ne de program kavramına sahiptir. Hangi talimatların çalıştırılabileceğini, çoğu zaman bir register’da tutulan işlemci mode’u belirler. İşletim sistemi kodu kernel mode’da çalışır, programları çalıştırmak için ise user mode’a geçer.
Bir ikili dosyayı çalıştırmak için işletim sistemi user mode’a geçer ve işlemciyi, RAM’deki giriş noktasına yönlendirir. Programların ayrıcalıkları kısıtlı olduğu için, dış dünyayla etkileşim kurmak istediklerinde kernel’dan yardım istemeleri gerekir. Syscall’lar, programların user mode’dan kernel mode’a ve işletim sistemi koduna geçmesinin standart yoludur.
Programlar bu syscall’ları genelde paylaşılan kütüphane fonksiyonları üzerinden kullanır. Bu fonksiyonlar, kontrolü kernel’a devreden software interrupt ya da mimariye özgü syscall talimatlarını sarar. Kernel işini yapar, sonra user mode’a ve program koduna geri dönülür.
Şimdi başta sorduğumuz ilk soruya dönelim:
CPU birden fazla process’i takip etmiyorsa ve sadece talimat üstüne talimat yürütüyorsa, neden tek bir programın içinde sıkışıp kalmıyor? Birden fazla program aynı anda nasıl çalışabiliyor?
Bunun cevabı, sevgili dostum, aynı zamanda Coldplay’in neden bu kadar popüler olduğunun da cevabı: saatler. Daha doğrusu timer’lar. Evet, bu şakayı yapmak istedim.
Bölüm 2: Zamanı Dilimle
Diyelim ki bir işletim sistemi yazıyorsun ve kullanıcıların aynı anda birden fazla program çalıştırabilmesini istiyorsun. Ama elinde çok çekirdekli havalı bir işlemci yok; dolayısıyla CPU aynı anda yalnızca tek bir talimat yürütebiliyor.
Neyse ki akıllı bir işletim sistemi geliştiricisisin. CPU’yu işlemler arasında sırayla paylaştırarak sahte paralellik yaratabileceğini fark ediyorsun. İşlemler arasında hızlı hızlı geçiş yapar ve her birine az miktarda çalışma süresi verirsen, CPU’yu tek bir işlem işgal etmeden sistem duyarlı kalabilir.
Peki program kodu çalışırken kontrolü geri nasıl alacaksın? Biraz araştırınca, çoğu bilgisayarda timer chip’ler bulunduğunu keşfediyorsun. Belirli bir süre geçince işletim sisteminin interrupt handler’ına geçişi tetikleyecek şekilde bu timer chip’leri programlayabiliyorsun.
Donanım Interrupt’ları
Bir önceki bölümde, kontrolü user-space programından işletim sistemine aktarmak için software interrupt’ların nasıl kullanıldığını görmüştük. Bunlara “software” interrupt denmesinin nedeni, bir program tarafından gönüllü olarak tetiklenmeleridir; yani normal fetch-execute cycle içinde çalışan makine kodu, CPU’ya kontrolü kernel’a bırakmasını söyler.
İşletim sistemi scheduler’ları, PIT gibi timer chip‘leri kullanarak multitasking için hardware interrupt üretir:
Program koduna geçmeden önce işletim sistemi, timer chip’i belirli bir süre sonra interrupt tetikleyecek şekilde ayarlar.
İşletim sistemi user mode’a geçer ve programın bir sonraki talimatına atlar.
Süre dolunca timer chip, kernel mode’a geçişi ve işletim sistemi kodunun devreye girmesini sağlayan bir hardware interrupt üretir.
İşletim sistemi artık mevcut programın durumunu kaydedebilir, başka bir programı yükleyebilir ve aynı döngüyü sürdürebilir.
Buna preemptive multitasking denir; bir işlemin zorla kesilmesine de preemption denir. Bu makaleyi tarayıcıda okurken aynı anda müzik de dinliyorsan, bilgisayarın muhtemelen bu döngüyü saniyede binlerce kez yapıyordur.
Timeslice Hesabı
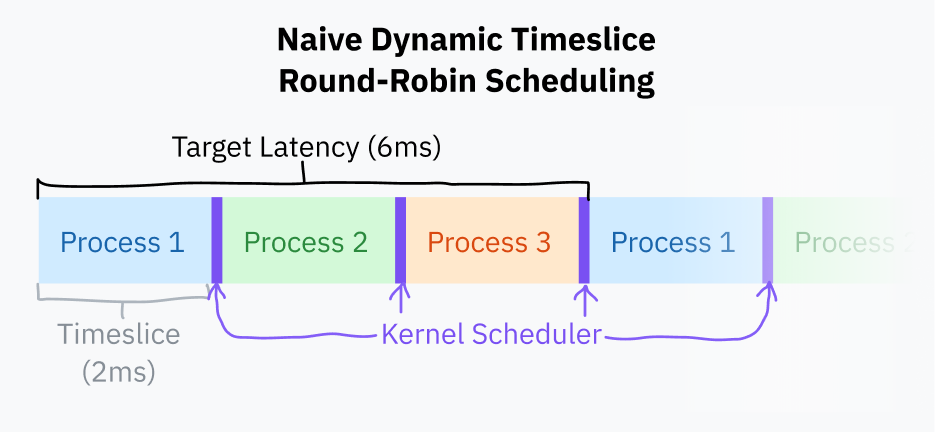
Timeslice, scheduler’ın bir işlemin kesilmeden önce çalışmasına izin verdiği süredir. Timeslice seçmenin en basit yolu, her işleme aynı süreyi vermek ve sırayla hepsi arasında dönmektir. Buna fixed-timeslice round-robin scheduling denir.
Küçük bir jargon notu
Timeslice için bazen “quantum” dendiğini biliyor muydun? Artık biliyorsun ve bunu uygun bir ortamda kullanarak teknik arkadaşlarını etkileyebilirsin. Bu makale boyunca her cümlede kuantum kelimesini kullanmadığım için takdir bekliyorum.
Linux kernel geliştiricileri ayrıca sabit frekanslı timer tick’lerini saymak için jiffy adlı zaman birimini kullanır. Timeslice uzunlukları da dâhil olmak üzere birçok şey bununla ölçülür. Linux’ta jiffy frekansı tipik olarak 1000 Hz’dir, ama kernel derlenirken değiştirilebilir.
Sabit timeslice yaklaşımının küçük ama önemli bir geliştirmesi, target latency değerini belirlemektir. Target latency, makul sayıda işlem varken bir işlemin preempt edildikten sonra tekrar CPU görmesi için geçmesini istediğin ideal en uzun süredir. Bunu kafada canlandırmak biraz zor; birazdan diyagramla daha net olacak.
Timeslice süresi, target latency’nin toplam görev sayısına bölünmesiyle hesaplanabilir. Bu, sabit süre vermekten daha iyidir; çünkü çalışan işlem sayısı az olduğunda gereksiz context switch’leri azaltır. Örneğin target latency 15 ms ve toplam 10 işlem varsa, her işlem yaklaşık 1,5 ms çalışır. Yalnızca 3 işlem varsa her biri 5 ms’lik daha uzun bir timeslice alır ve yine aynı target latency içinde sıraya girmiş olur.
Context switch pahalıdır; çünkü mevcut programın tüm durumunu kaydetmeyi ve başka bir programın durumunu geri yüklemeyi gerektirir. Çok küçük timeslice’lar, işlemler gereğinden sık değiştiği için performansı düşürebilir. Bu yüzden scheduler’larda genelde bir minimum granularity sınırı bulunur. Bu sınır devreye girdiğinde target latency aşılabilir, ama sistem aşırı sık context switch yapmaktan kurtulur.
Bu makale yazıldığında Linux scheduler’ı 6 ms target latency ve 0,75 ms minimum granularity kullanıyordu.
Bu temel timeslice hesabıyla çalışan round-robin scheduling, günümüz makinelerinin yaptıklarına fena halde yakındır. Yine de biraz naiftir; çoğu işletim sistemi işlem önceliklerini, deadline’ları ve başka sinyalleri de dikkate alan daha karmaşık scheduler’lar kullanır. Linux, 2007’den beri Completely Fair Scheduler kullanıyor. CFS, görevleri önceliklendirmek ve CPU süresini bölüştürmek için daha sofistike tekniklere başvurur.
İşletim sistemi bir işlemi her preempt ettiğinde, yeni programın kayıtlı yürütme bağlamını da yüklemesi gerekir. Buna bellek bağlamı da dâhildir. Bu, CPU’ya sanal adresleri fiziksel adreslere çevirirken farklı bir page table kullanmasını söyleyerek yapılır. Programların birbirlerinin belleğine erişmesini engelleyen şey de budur; bu tavşan deliğine Bölüm 5 ve Bölüm 6‘da gireceğiz.
Not #1: Kernel’in Preempt Edilebilirliği
Şu ana kadar yalnızca user-space işlemlerin preempt edilmesinden söz ettik. Oysa bir syscall’ın işlenmesi ya da driver kodunun yürütülmesi çok uzun sürerse, kernel kodu da programları yavaşlatabilir.
Linux dâhil modern kernel’lar preemptive kernel yaklaşımını benimser. Yani gerektiğinde kernel kodunun kendisi de kesilebilir ve scheduler tarafından başka bir işe geçilebilir.
Kernel ya da driver yazmıyorsan bunu ayrıntılı bilmen şart değil, ama okuduğum neredeyse her kaynak buna değiniyordu; ben de zinciri bozmamak istedim. Fazladan bağlam nadiren zarardır.
Not #2: Kısa Bir Tarih Dersi
Eski işletim sistemleri, buna klasik Mac OS ve NT öncesi bazı Windows sürümleri de dâhil, preemptive multitasking yerine onun öncülü olan başka bir modeli kullanıyordu. İşletim sisteminin “şimdi seni keseceğim” demesi yerine, programların kendisi gönüllü olarak kontrolü bırakıyordu. Yani bir software interrupt tetikleyip “istersen şimdi başka bir programı çalıştırabilirsin” diyordu. İşletim sisteminin kontrolü geri alıp başka sürece geçmesinin tek yolu buydu.
Buna cooperative multitasking denir. Büyük kusurları vardır: kötü niyetli ya da kötü yazılmış programlar tüm sistemi kolayca dondurabilir ve zaman hassasiyetinin önemli olduğu işlerde kararlı davranış elde etmek neredeyse imkânsızdır. Bu yüzden teknoloji dünyası uzun zaman önce preemptive multitasking’e geçti ve geriye dönüp bakmadı.
Bölüm 3: Bir Program Nasıl Çalıştırılır?
Şimdiye kadar CPU’ların executable dosyalardan yüklenen makine kodunu nasıl yürüttüğünü, ring tabanlı güvenliğin ne olduğunu ve syscall’ların nasıl çalıştığını gördük. Bu bölümde ise Linux kernel’ının içine biraz daha dalıp programların gerçekten nasıl yüklendiğini ve çalıştırıldığını anlamaya çalışacağız.
Özellikle x86-64 üzerindeki Linux’a bakacağız. Neden?
Linux, masaüstünden mobile ve sunucuya kadar geniş kullanım alanına sahip tam teşekküllü bir üretim işletim sistemidir. Üstelik açık kaynak olduğu için doğrudan kaynak koda bakarak ilerlemek çok kolaydır. Bu makalede kernel koduna bol bol referans vereceğim.
x86-64, modern masaüstü bilgisayarların büyük kısmında kullanılan mimaridir ve pek çok kodun hedefidir. Burada göreceğimiz x86-64’e özgü ayrıntıların önemli kısmı yine de daha genel fikirlere açılır.
Öğreneceğimiz şeylerin çoğu, ayrıntılar değişse de başka işletim sistemlerine ve mimarilere de kolayca genellenebilir.
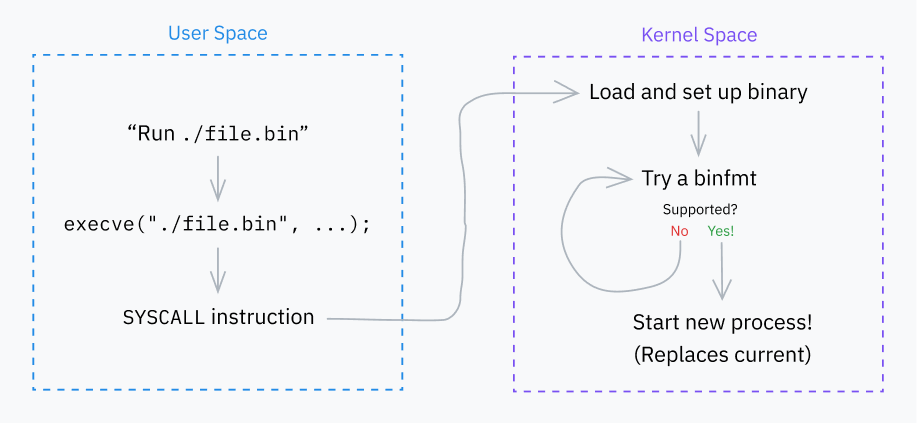
Exec Syscall’larının Temel Davranışı
Çok önemli bir sistem çağrısıyla başlayalım: execve. Bir programı yükler ve başarılı olursa mevcut işlemi o programla değiştirir. Birkaç sistem çağrısı (execlp, execvpe, vb.) daha mevcut, ancak hepsi çeşitli şekillerde execve‘nin üzerinde katmanlanıyor.
Bir not: execveat
execve aslında, yapılandırma açısından daha genel olan execveat syscall’ı üzerine kuruludur. Bu syscall bazı ek seçeneklerle program yürütmeye izin verir. Biz sadelik adına çoğunlukla execve üzerinden konuşacağız; pratikte fark, execve‘nin execveat için birtakım varsayılanlar belirlemesidir.
ve ne demek diye merak ediyorsan: v, argüman vektörü olan argv‘yi; e ise environment vektörü olan envp‘yi temsil eder. Diğer exec varyantları da farklı çağrı imzalarını son eklerle ayırt eder. execveat içindeki at ise, programın hangi konuma göre çalıştırılacağını belirtebildiği için oradadır.
filename, çalıştırılacak programın yolunu belirtir.
argv, null-terminated bir argüman listesidir; yani son öğe null pointer’dır. C’deki main fonksiyonunda gördüğün argc değeri aslında daha sonra bu listeden hesaplanır.
envp ise programın ortam değişkenlerini taşıyan, yine null-terminated başka bir listedir. Bunlar… geleneksel olarak KEY=VALUE çiftleridir. Geleneksel olarak. Bilgisayarları seviyorum.
Küçük ama önemli bir ayrıntı: Bir programın ilk argümanının program adı olması diye bildiğimiz şey sadece bir konvansiyondur. execve bunu kendiliğinden ayarlamaz. İlk argüman, çağıran kod argv içine ne koyduysa odur; ister program adı olsun ister bambaşka bir şey.
Yine de ilginç biçimde, bazı kod yollarında execve ve çevresindeki logic, argv[0]‘ın program adını temsil ettiğini varsayar. Birazdan interpreted dillerden söz ederken bunun bir örneğini göreceğiz.
Adım 0: Tanım
Sistem çağrılarının nasıl çalıştığını zaten biliyoruz, ancak gerçek dünyadan bir kod örneğini hiç görmedik! execve‘nin başlık altında nasıl tanımlandığını görmek için Linux çekirdeğinin kaynak koduna bakalım:
SYSCALL_DEFINE3, 3 bağımsız değişkenli sistem çağrısının kodunu tanımlamak için kullanılan bir makrodur.
arity’nin makro adına neden sabit kodlandığını merak ettim; Google’da araştırdım ve bunun bazı güvenlik açıklarını düzeltmeye yönelik bir geçici çözüm olduğunu öğrendim.
Dosya adı argümanı, dizeyi kullanıcı alanından çekirdek alanına kopyalayan ve bazı kullanım izleme işlemleri yapan bir getname() işlevine iletilir. include/linux/fs.h içinde tanımlanan bir filename yapısını döndürür. Kullanıcı alanındaki orijinal dizeye yönelik bir işaretçinin yanı sıra, çekirdek alanına kopyalanan değere yönelik yeni bir işaretçiyi de saklar:
struct filename {constchar*name; /* pointer to actual string */const __user char*uptr; /* original userland pointer */int refcnt;struct audit_names *aname;constchar iname[];};
execve sistem çağrısı daha sonra bir do_execve() işlevini çağırır. Bu da bazı varsayılanlarla do_execveat_common() öğesini çağırır. Daha önce bahsettiğim execveat sistem çağrısı da do_execveat_common()‘yi çağırır ancak kullanıcı tarafından sağlanan daha fazla seçenekten geçer.
Aşağıdaki kod parçasına hem do_execve hem de do_execveat tanımlarını ekledim:
execveat çağrısında bir file descriptor (bir kaynağa işaret eden kimlik türü) syscall’a ve oradan da do_execveat_common fonksiyonuna geçer. Bu descriptor, programın hangi dizine göre yürütüleceğini belirler.
execve tarafında ise file descriptor argümanı için özel bir değer kullanılır: AT_FDCWD. Bu, Linux kernel’ında path’lerin current working directory’ye göre yorumlanmasını söyleyen ortak bir sabittir. File descriptor alan fonksiyonlarda genelde if (fd == AT_FDCWD) { /* special codepath */ } benzeri açık bir kontrol görürsün.
Adım 1: Kurulum
Artık çekirdek işlev yürütme programının yürütülmesi olan do_execveat_common‘ye ulaştık. Bu işlevin ne yaptığına dair daha büyük bir resim görünümü elde etmek için koda bakmaktan kısa bir adım atacağız.
do_execveat_common‘nin ilk büyük işi linux_binprm adında bir yapı kurmaktır. Yapı tanımının tamamının bir kopyasını eklemeyeceğim, ancak incelenecek birkaç önemli alan var:
Yeni programa sanal bellek yönetimini hazırlamak için mm_struct ve vm_area_struct gibi veri yapıları tanımlanmıştır.
argc ve envc hesaplanır ve programa aktarılmak üzere saklanır.
filename ve interp sırasıyla programın ve yorumlayıcısının dosya adını saklar. Bunlar birbirine eşit olarak başlar ancak bazı durumlarda değişebilir: Böyle bir durum, yorumlanmış komut dosyalarının shebang ile çalıştırılmasıdır. Örneğin bir Python programını çalıştırırken, filename kaynak dosyayı işaret eder ancak interp Python yorumlayıcısının yoludur.
buf, yürütülecek dosyanın ilk 256 baytıyla dolu bir dizidir. Dosyanın formatını tespit etmek ve komut dosyası shebanglarını yüklemek için kullanılır.
Gördüğümüz gibi uzunluk BINPRM_BUF_SIZE sabitiyle tanımlanıyor. Kod tabanında bunu arattığında, include/uapi/linux/binfmts.h içinde şu tanıma ulaşıyorsun:
Böylece çekirdek, yürütülen dosyanın açılış 256 baytını bu bellek arabelleğine yükler.
Bir yana: UAPI nedir?
Yukarıdaki yolun /uapi/ içerdiğini fark etmiş olabilirsin. Peki bu sabit neden linux_binprm yapısıyla aynı dosyada tanımlanmıyor?
UAPI, “kullanıcı alanı API’si” anlamına gelir. Bu durumda, birisinin arabellek uzunluğunun çekirdeğin genel API’sinin bir parçası olması gerektiğine karar verdiği anlamına gelir. Teorik olarak, UAPI’nin kullanıcı alanına açık olduğu her şey ve UAPI olmayan her şey çekirdek koduna özeldir.
Çekirdek ve kullanıcı alanı kodu başlangıçta tek bir karmakarışık kütle halinde bir arada mevcuttu. 2012 yılında, sürdürülebilirliği iyileştirme girişimi olarak UAPI kodu ayrı bir dizinde yeniden düzenlendi.
Adım 2: Binfmt’ler
Çekirdeğin bir sonraki büyük işi bir grup “binfmt” (ikili format) işleyicisini yinelemektir. Bu işleyiciler fs/binfmt_elf.c ve fs/binfmt_flat.c gibi dosyalarda tanımlanır. Çekirdek modülleri ayrıca havuza kendi binfmt işleyicilerini de ekleyebilir.
Her işleyici, linux_binprm yapısını alan bir load_binary() işlevini kullanıma sunar ve işleyicinin programın formatını anlayıp anlamadığını kontrol eder.
Bu genellikle arabellekte sihirli sayılar aramayı, programın başlangıcının kodunu çözmeye çalışmayı (yine ara bellekten) ve/veya dosya uzantısını kontrol etmeyi içerir. İşleyici formatı destekliyorsa programı yürütmeye hazırlar ve bir başarı kodu döndürür. Aksi halde erkenden çıkar ve bir hata kodu döndürür.
Çekirdek, başarılı olana ulaşana kadar her binfmt’nin load_binary() işlevini dener. Bazen bunlar yinelemeli olarak çalışır; örneğin, bir betiğin belirlenmiş bir yorumlayıcısı varsa ve bu yorumlayıcının kendisi de bir betikse, hiyerarşi binfmt_script > binfmt_script > binfmt_elf olabilir (burada ELF, zincirin sonunda çalıştırılabilir formattır).
Format Vurgulama: Komut Dosyaları
Linux’un desteklediği pek çok formattan binfmt_script özellikle bahsetmek istediğim ilk format.
Hiç shebang satırı gördün mü? Hani bazı script’lerin en başında interpreter yolunu söyleyen şu satır:
1
#!/bin/bash
Ben uzun süre bunun shell tarafından ele alındığını sanmıştım. Meğer öyle değilmiş. Shebang’ler aslında kernel özelliği ve script’ler de diğer programlarla aynı syscall’lar üzerinden yürütülüyor. Bilgisayarlar gerçekten çok havalı.
fs/binfmt_script.c dosyasının, bir dosyanın #! ile başlayıp başlamadığını nasıl kontrol ettiğine bak:
/* Not ours to exec if we don't start with "#!". */if ((bprm->buf[0] !='#') || (bprm->buf[1] !='!'))return-ENOEXEC;
Dosya bir shebang ile başlıyorsa, binfmt işleyicisi yorumlayıcı yolunu ve yoldan sonraki boşlukla ayrılmış bağımsız değişkenleri okur. Yeni bir satıra veya arabelleğin sonuna ulaştığında durur.
Burada iki ilginç, riskli şey oluyor.
Birincisi, linux_binprm içindeki ve dosyanın ilk 256 baytıyla doldurulan buffer’ı hatırlıyor musun? Yürütülebilir formatı tespit etmek için kullanılan bu aynı buffer, binfmt_script içinde shebang satırlarını okumak için de kullanılıyor.
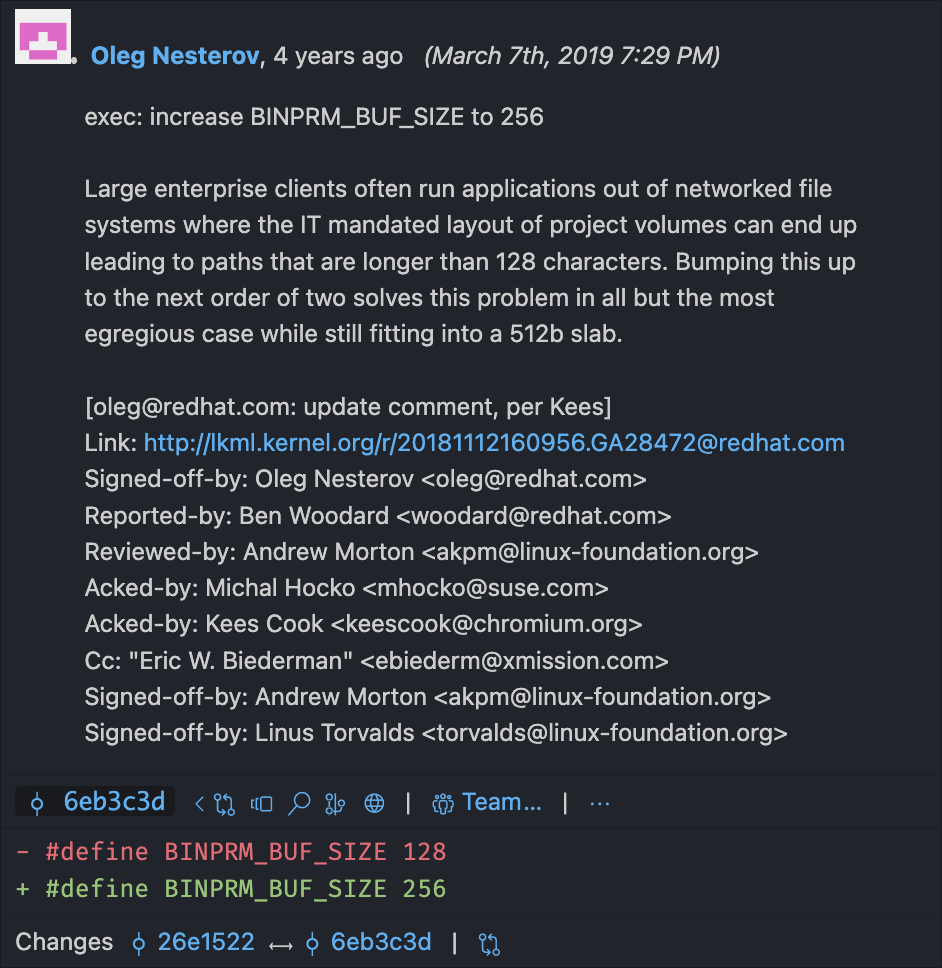
Araştırma yaparken buffer’ın bir zamanlar 128 bayt olduğunu söyleyen kaynaklara rastladım. Sonra fark ettim ki bu uzunluk sonradan 256’ya çıkarılmış. Nedenini merak edip BINPRM_BUF_SIZE satırı için Git blame baktım. Sonuç şuydu:
BİLGİSAYARLAR ÇOK HARİKA.
Shebang kernel tarafından işlendiği ve tüm dosya yerine yalnızca buf içinden okunduğu için, shebang satırı her zamanbuf uzunluğuyla sınırlıdır. Yani bugün kendi Linux makinenizde 256 karakterden uzun bir shebang yazarsanız, 256 karakterden sonrası dümdüz kaybolur.
Böyle bir bug yaşadığını düşün. Kodunu bozan şeyin kök nedenini arıyorsun. Sonra problemin, Linux kernel’ının derinliklerinde duran bir buffer uzunluğu sınırı olduğunu öğreniyorsun. Büyük kurumsal path’lerde bir kısmın gizemli biçimde silindiğini fark eden bir sonraki BT çalışanına şimdiden sabır diliyorum.
İkinci riskli şey: Az önce argv[0]‘ın program adı olmasının sadece bir konvansiyon olduğunu ve çağıranın istediği argv‘yi verebileceğini konuşmuştuk ya? İşte binfmt_script, argv[0]‘ın program adı olduğunu varsayan yerlerden biri.
Bu handler, önce argv[0]‘ı siler ve ardından argv‘nin başına şunları ekler:
argv güncellendikten sonra handler, linux_binprm.interp değerini interpreter yoluna ayarlayarak yürütme hazırlığını tamamlar. Son olarak programın başarıyla hazırlandığını göstermek için 0 döndürür.
Format Vurgulama: Çeşitli Tercümanlar
Bir başka ilginç işleyici ise binfmt_misc. /proc/sys/fs/binfmt_misc/ adresine özel bir dosya sistemi monte ederek, kullanıcı alanı yapılandırması aracılığıyla bazı sınırlı formatları ekleme olanağını açar. Programlar, kendi işleyicilerini eklemek için bu dizindeki dosyalara özel olarak biçimlendirilmiş yazma işlemleri gerçekleştirebilir. Her konfigürasyon girişi şunları belirtir:
Dosya formatları nasıl tespit edilir. Bu, belirli bir konumdaki sihirli bir sayıyı veya aranacak bir dosya uzantısını belirtebilir.
Çalıştırılabilir bir yorumlayıcının yolu. Yorumlayıcı argümanlarını belirtmenin bir yolu yoktur, bu nedenle eğer istenirse bir sarmalayıcı komut dosyasına ihtiyaç vardır.
binfmt_misc‘nin argv‘yi nasıl güncellediğini belirten bir tane de dahil olmak üzere bazı yapılandırma işaretleri.
Bu binfmt_misc sistemi genellikle Java kurulumları tarafından kullanılır ve sınıf dosyalarını 0xCAFEBABE sihirli baytlarına göre ve JAR dosyalarını uzantılarına göre algılayacak şekilde yapılandırılmıştır. Benim özel sistemimde, Python bayt kodunu .pyc uzantısıyla algılayan ve bunu uygun işleyiciye aktaran bir işleyici yapılandırılmıştır.
Bu, program yükleyicilerinin yüksek ayrıcalıklı çekirdek kodu yazmaya gerek kalmadan kendi formatları için destek eklemelerine izin vermenin oldukça güzel bir yoludur.
Sonunda (Linkin Park Şarkısı Olan Değil)
Bir exec sistem çağrısı her zaman iki yoldan biriyle sonuçlanır:
Belki de birkaç katmandan oluşan komut dosyası yorumlayıcılarından sonra, sonunda anlayabileceği yürütülebilir bir ikili formata ulaşacak ve bu kodu çalıştıracaktır. Bu noktada eski kod değiştirildi.
… ya da tüm seçeneklerini tüketecek ve çağıran programa, kuyruğu bacaklarının arasında olacak şekilde bir hata kodu döndürecektir.
Unix benzeri bir sistem kullandıysan, terminalden çalıştırılan shell script’lerin bazen ne shebang ne de .sh uzantısı olmadan yine de yürütüldüğünü fark etmiş olabilirsin. Elinin altında Unix benzeri bir terminal varsa hemen deneyebilirsin:
(chmod +x, işletim sistemine dosyanın çalıştırılabilir olduğunu söyler. Bunu yapmazsan dosyayı yürütemezsin.)
Peki shell script neden shell script olarak çalışıyor? Kernel’ın format handler’larının, üzerinde açık bir etiket olmayan shell script’i güvenilir biçimde tanıması mümkün görünmüyor.
Çünkü bu davranış aslında kernel’ın işi değil. Bu, shell tarafında başarısız bir exec çağrısını ele almanın yaygın yolu.
Bir dosyayı shell üzerinden çalıştırdığında exec syscall’ı başarısız olursa, çoğu shell dosyayı yeniden denemek için bu kez bir shell process’i başlatır ve dosya adını ona ilk argüman olarak verir. Bash genelde kendi kendisini interpreter olarak kullanır; ZSH ise çoğu zaman sh‘in işaret ettiği şeyi, yani genellikle Bourne shell‘i çağırır.
Bu davranış o kadar yaygındır ki, Unix sistemleri arasında taşınabilirliği hedefleyen eski standartlardan biri olan POSIX‘te bile yer alır. POSIX bugün her araç ve sistem tarafından birebir takip edilmese de, pek çok davranış hâlâ onun izini taşır.
Bir exec syscall’ı [ENOEXEC] ile eşdeğer bir hatayla başarısız olursa, kabuk komut adını ilk argüman olarak verdiği yeni bir kabuk süreci başlatır ve kalan argümanları da bu yeni kabuğa aktarır. Çalıştırılmak istenen dosya bir metin dosyası değilse kabuk bu denemeyi atlayabilir; bu durumda hata yazdırır ve 126 çıkış kodu döndürür.
Artık execve‘ı epey iyi anlıyoruz. Çoğu yolun sonunda kernel, çalıştırılacak makine kodunu içeren son programa ulaşır. Ama koda atlamadan önce genelde bir kurulum süreci gerekir; örneğin programın farklı bölümlerinin bellekte doğru yerlere yüklenmesi gerekir. Her programın farklı türde ve miktarda belleğe ihtiyacı olduğundan, bir programın nasıl hazırlanacağını tarif eden standart dosya formatlarına ihtiyaç duyarız. Linux pek çok formatı destekler ama açık ara en yaygın olanı ELF‘dir (Executable and Linkable Format).
Linux’ta bir uygulama ya da komut satırı programı çalıştırdığında, bunun bir ELF binary olması çok olasıdır. macOS tarafında fiili format Mach-O‘dur. Mach-O da temelde ELF ile aynı işi yapar, sadece farklı biçimde düzenlenmiştir. Windows’ta ise .exe dosyaları, yine benzer kavramları farklı bir paketle sunan Portable Executable formatını kullanır.
Linux kernel’ında ELF binary’leri, diğer birçok handler’dan çok daha karmaşık olan ve binlerce satır koda sahip binfmt_elf handler’ı tarafından işlenir. Bu kod, ELF dosyasındaki ayrıntıları ayrıştırmaktan ve bunları süreci belleğe yerleştirip çalıştırmak için kullanmaktan sorumludur.
Binfmt handler’larını satır sayısına göre sıralamak için biraz command-line kung fu yaptım:
binfmt_elf‘in ELF dosyalarını nasıl çalıştırdığına daha derin girmeden önce, dosya formatının kendisine bakalım. ELF dosyaları genelde dört ana parçadan oluşur:
ELF Header
Her ELF dosyasının bir ELF header‘ı vardır. Bunun görevi, binary hakkında temel bilgileri taşımaktır:
Hangi işlemci mimarisi için üretildiği. ELF dosyaları ARM, x86 ve başka mimariler için makine kodu taşıyabilir.
Dosyanın kendi başına çalıştırılabilir bir executable mı olduğu, yoksa başka programlar tarafından yüklenecek bir shared library mi olduğu.
Executable’ın entry point’i. ELF’nin sonraki bölümleri, verilerin bellekte nereye yükleneceğini tarif eder; entry point ise tüm süreç hazır olduğunda ilk makine kodu talimatının hangi adreste olduğunu söyler.
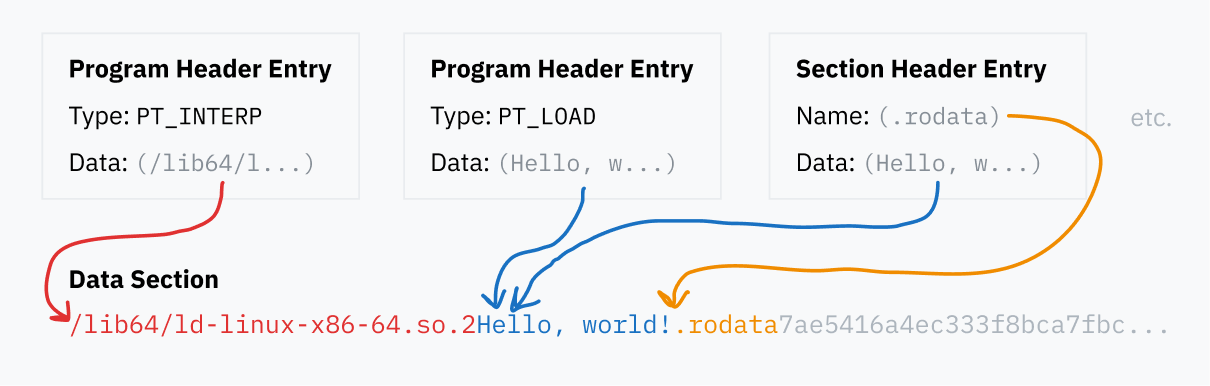
ELF header her zaman dosyanın başında bulunur. Program header table ile section header table’ın dosya içinde nerede olduğunu bildirir. Bu tablolar da dosyanın başka yerlerinde duran veri bloklarına işaret eder.
Program Header Table
Program header table, binary’nin çalışma zamanında nasıl yükleneceğini ve yürütüleceğini anlatan bir dizi girdiden oluşur. Her girdinin, ne tür bilgi taşıdığını belirten bir tür alanı vardır. Örneğin PT_LOAD, belleğe yüklenmesi gereken veri segmentini ifade eder; PT_NOTE ise herhangi bir yere yüklenmesi gerekmeyen serbest biçimli bilgi notlarını temsil eder.
Her giriş, verisinin dosya içinde nerede olduğunu ve bazen belleğe nasıl taşınacağını belirtir:
Verinin ELF dosyası içindeki konumunu söyler.
Verinin belleğe hangi sanal adresten yüklenmesi gerektiğini belirtebilir. Segment belleğe yüklenmeyecekse bu alan genelde boş kalır.
İki ayrı alan verinin boyutunu tutar: biri dosyadaki boyut, diğeri ise bellekte ayrılacak bölgenin boyutudur. Bellek boyutu dosya boyutundan büyükse, eksik kısım sıfırlarla doldurulur. Bu, çalışma zamanında sıfırlanmış bir bellek bölgesi isteyen programlar için kullanışlıdır; bu tür alanlara genelde BSS denir.
Son olarak, bir bayrak alanı belleğe yüklendiğinde hangi işlemlere izin verileceğini belirtir: PF_R okunabilir, PF_W yazılabilir, PF_X ise çalıştırılabilir demektir.
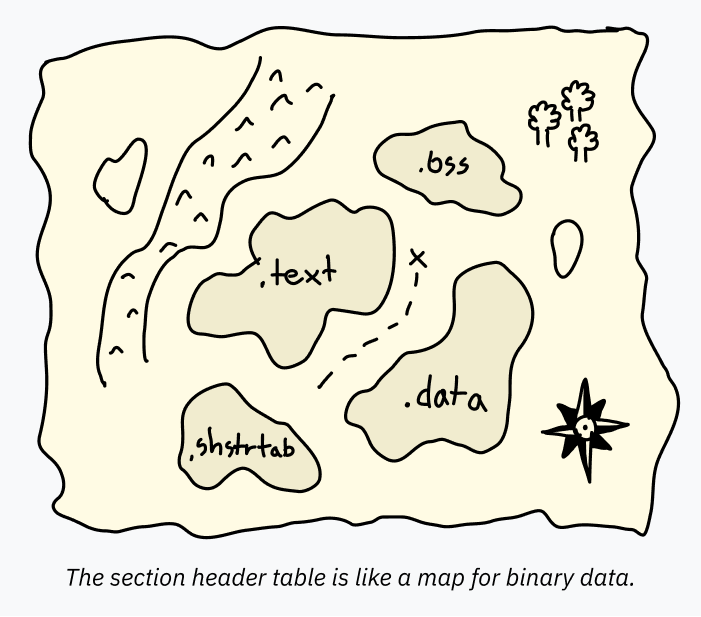
Section Header Table
Section header table, section‘lar hakkında bilgi taşıyan bir dizi girdidir. Bunu, ELF dosyasındaki verileri gösteren bir harita gibi düşünebilirsin. Böylece debugger gibi araçlar, farklı veri bölgelerinin ne işe yaradığını anlayabilir.
Örneğin program header table, belleğe birlikte yüklenecek geniş bir veri aralığı tanımlayabilir. Tek bir PT_LOAD girdisi hem kodu hem de global değişkenleri içerebilir. Programın çalışması için bunların ayrıca tek tek işaretlenmesi gerekmez; CPU entry point’ten başlar ve program ne zaman nereye erişmek istiyorsa oraya gider. Ama analiz yapmak isteyen bir debugger’ın her alanın tam olarak nerede başladığını ve bittiğini bilmesi gerekir; yoksa hello yazan bir metni kod sanıp çözmeye çalışabilir ve doğal olarak ortalık dağılır. İşte bu bilgi section header table’da tutulur.
Genelde ELF dosyalarında bulunsa da, section header table aslında isteğe bağlıdır. Tamamen kaldırılmış olsa bile ELF binary’leri düzgün çalışabilir. Kodlarının ne yaptığını zorlaştırmak isteyen geliştiriciler bazen section header table’ı bilerek siler ya da bozar; kötü biçimlendirilmiş ELF başlıklarıyla analizden kaçma diye bir dünya bile var.
Her section’ın bir adı, türü ve nasıl çözümlenip kullanılacağını anlatan bazı bayrakları vardır. Geleneksel isimler çoğu zaman nokta ile başlar. Sık görülen örnekler şunlardır:
.text: belleğe yüklenecek ve CPU’da yürütülecek makine kodu. Türü SHT_PROGBITS olur; çalıştırılabilir olduğunu belirtmek için SHF_EXECINSTR, belleğe yükleneceğini belirtmek için de SHF_ALLOC bayrakları kullanılır. (İsmi seni şaşırtmasın; bu bölüm hâlâ dümdüz binary makine kodudur. “Metin” olmadığı hâlde adına .text denmesi bana her zaman biraz tuhaf gelmiştir.)
.data: executable içine gömülmüş, başlatılmış veriler. Örneğin bazı metinleri taşıyan global bir değişken burada bulunabilir. Low-level kod yazıyorsan static verilerin gittiği yer kabaca burasıdır. Bunun da türü SHT_PROGBITS‘tir; bayrakları genelde SHF_ALLOC ve SHF_WRITE olur.
.bss: Daha önce sıfırla başlatılmış ama dosyada fiziksel olarak yer kaplamayan bellek alanlarından söz etmiştik. ELF dosyasına yığınla boş bayt koymak israf olacağı için bunun için özel bir temsil kullanılır. Debugging açısından bu alanların da görünür olması faydalıdır; bu yüzden section header table’da ayrılacak bellek boyutunu belirten bir giriş bulunur. Türü SHT_NOBITS, bayrakları ise SHF_ALLOC ve SHF_WRITE olur.
.rodata: Yazılabilir olmaması dışında .data gibidir. Çok basit bir C programındaki "Hello, world!" dizesi burada durabilir; onu ekrana yazdıran makine kodu ise .text içinde olur.
.shstrtab: Bu hoş bir implementasyon detayıdır. Section isimleri (.text ya da .shstrtab gibi) doğrudan section header table içine yazılmaz. Bunun yerine her girdi, dosyada isminin tutulduğu yere giden bir offset saklar. Böylece tablodaki tüm girdiler sabit boyutta kalır ve ayrıştırılmaları kolaylaşır. Bu isim dizelerinin tamamı, SHT_STRTAB türündeki ayrı bir .shstrtab section’ında tutulur.
Veri
Program ve section header girdilerinin tamamı, ister belleğe yüklenecek veri olsun ister program kodunun nerede durduğunu gösteren referans olsun, ELF dosyası içindeki veri bloklarına işaret eder. Bu parçaların tamamı ELF dosyasının veri alanında bulunur.
Linking’e Kısa Bir Bakış
Şimdi yeniden binfmt_elf koduna dönelim: kernel, program header table’daki iki tür girdiye özellikle dikkat eder.
PT_LOAD girdileri, .text ve .data gibi program verilerinin bellekte nereye yerleştirileceğini belirtir. Kernel, programı CPU’nun yürütebilmesi için bu girdileri okuyup ilgili verileri belleğe yükler.
Kernel’ın önem verdiği diğer program header türü ise PT_INTERP‘tir; bu alan, “dynamic linking runtime”ı ya da daha pratik adıyla dynamic loader’ı işaret eder.
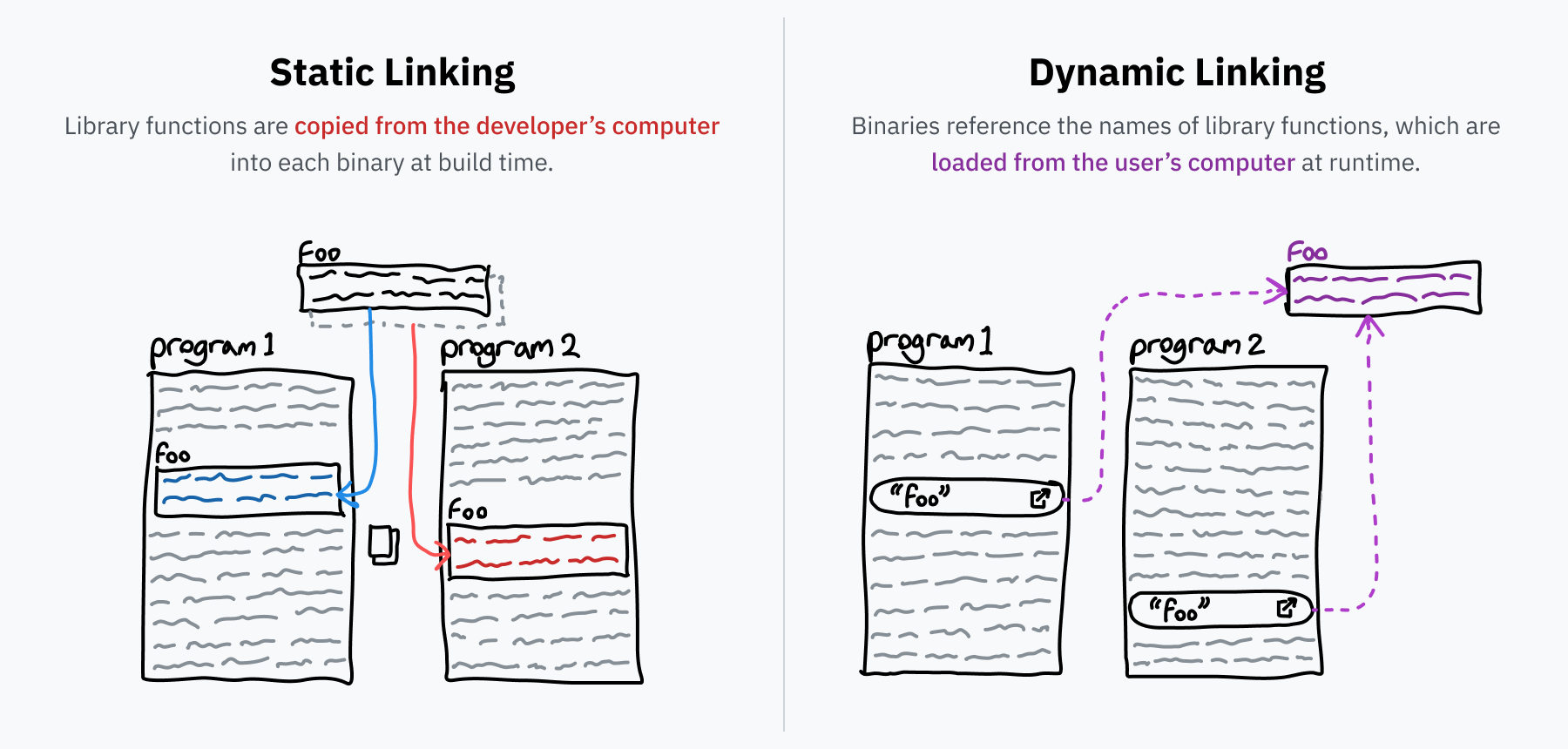
Dynamic linking’den önce genel olarak “linking”den söz edelim. Programcılar, programlarını yeniden kullanılabilir kütüphaneler üzerine kurar; biraz önce adı geçen libc bunun klasik örneğidir. Kaynak kodunu executable binary’ye dönüştürürken linker adlı program, ihtiyaç duyulan library kodunu bulur ve bunları binary’ye ekler. Dış kodun doğrudan dağıtılan dosyaya dâhil edildiği bu yönteme static linking denir.
Ama bazı kütüphaneler aşırı yaygındır. Libc, sistemle konuşmanın standart yolu olduğu için neredeyse her programda vardır. Bilgisayardaki her programa ayrı bir libc kopyası gömmek hem alan israfıdır hem de bakım açısından kötüdür. Tek bir yerde güncelleme yapıp bunu her programa yansıtabilmek çok daha iyidir. Dynamic linking bu derdin çözümüdür.
Static linked bir programın, bar adlı bir kütüphaneden foo fonksiyonuna ihtiyacı varsa, binary kendi içinde foo‘nun bir kopyasını taşır. Dynamic linked durumda ise binary yalnızca “Benim bar kütüphanesindeki foo‘ya ihtiyacım var” diyen bir referans tutar. Program çalıştırıldığında bar kütüphanesinin sistemde yüklü olduğu varsayılır ve foo‘nun makine kodu gerektiğinde belleğe alınır. Sistemindeki bar güncellenirse, programın kendisini yeniden derlemeye gerek kalmadan bir sonraki çalıştırmada yeni kod kullanılabilir.
Gerçek Hayatta Dynamic Linking
Linux’ta bar gibi dynamic link edilebilen kütüphaneler genelde .so (Shared Object) uzantılı dosyalar hâlinde paketlenir. Bu .so dosyaları da programlar gibi ELF dosyalarıdır; ELF header’ın dosyanın executable mı yoksa library mi olduğunu belirten bir alan taşıdığını hatırlarsın. Ayrıca shared object’lerin section header table’ında, hangi sembollerin dışa açıldığını ve dynamic link edilebildiğini anlatan .dynsym adlı bir section bulunur.
Windows’ta bar gibi kütüphaneler .dll (dynamic link library) dosyaları olarak paketlenir. macOS ise .dylib (dynamically linked library) uzantısını kullanır. Bunlar, tıpkı macOS uygulamaları ve Windows .exe dosyaları gibi ELF’den biraz farklı biçimlendirilmiştir; ama temel fikir aynıdır.
Static linking ile dynamic linking arasındaki ilginç farklardan biri şudur: Static linking’de kütüphanenin yalnızca gerçekten kullanılan bölümleri binary’ye girer ve belleğe yüklenir. Dynamic linking’de ise kütüphanenin tamamı yüklenir. İlk bakışta bu daha verimsiz görünebilir, ama modern işletim sistemleri aynı kütüphaneyi belleğe bir kez yükleyip ardından kod bölümünü birden çok process arasında paylaşabildiği için aslında daha fazla alan tasarrufu sağlar. Durum bilgisi process’e özel olduğu için yalnızca kod paylaşılır, ama buna rağmen tasarruf onlarca hatta yüzlerce megabayt RAM seviyesine çıkabilir.
Yürütme
Şimdi ELF dosyalarını çalıştıran kernel’a geri dönelim: Eğer yürütülen binary dynamic linked ise, işletim sistemi onun koduna doğrudan atlayamaz; çünkü ihtiyaç duyduğu kodun bir kısmı henüz yerinde değildir. Unutma: dynamic linked programlar, ihtiyaç duydukları library fonksiyonlarına yalnızca referans taşır.
Programı gerçekten başlatabilmek için işletim sistemi hangi kütüphanelere ihtiyaç duyulduğunu bulmalı, onları yüklemeli, isim olarak duran referansları gerçek adreslere çözmeli ve sonra gerçek program kodunu başlatmalıdır. Bu iş, ELF formatının ayrıntılarıyla yoğun şekilde uğraşan karmaşık bir süreçtir; bu yüzden genelde kernel’ın içinde değil, ayrı bir user-space programda yürür. ELF dosyaları, program header table’daki PT_INTERP girdisinde hangi loader’ı kullanmak istediklerini belirtir; tipik örneklerden biri /lib64/ld-linux-x86-64.so.2‘dir.
Kernel, ELF header’ı okuyup program header table’ı taradıktan sonra yeni programın bellek düzenini hazırlayabilir. İlk iş olarak tüm PT_LOAD segmentlerini belleğe yerleştirir; böylece programın statik verileri, BSS alanı ve makine kodu hazır olur. Program dynamic linked ise, kernel ayrıca ELF interpreter’ı (PT_INTERP) da yüklemek zorundadır; yani onun verileri, BSS alanı ve kodu da belleğe taşınır.
Sonrasında kernel, user space’e dönerken CPU’nun geri yükleyeceği instruction pointer’ı ayarlar. Executable dynamic linked ise, instruction pointer ELF interpreter’ın bellekteki giriş noktasına konur. Aksi takdirde doğrudan executable’ın entry point’ine ayarlanır.
Kernel artık syscall’dan dönmeye neredeyse hazırdır. Unutma, hâlâ execve içindeyiz. Program başlarken okuyabilsin diye argc, argv ve environment değişkenlerini stack’e yazar.
Bir de register temizliği yapılır. Kernel, syscall işlenmeden önce user space register’larının değerlerini, dönüşte geri yüklenmek üzere stack’te saklar. User space’e dönmeden hemen önce bu alanı temizler.
Sonunda syscall biter ve kernel tekrar user space’e döner. Kayıtları geri yükler ve saklı instruction pointer’a atlar. Bu instruction pointer artık yeni programın ya da gerekiyorsa ELF interpreter’ın giriş noktasıdır; yani mevcut süreç fiilen değiştirilmiş olur.
Bölüm 5: Bilgisayarındaki Çevirmen
Şimdiye kadar bellekten söz ederken biraz eli gevşek davrandım. Örneğin ELF dosyaları verilerin yükleneceği belirli bellek adreslerini söylüyor; peki farklı process’lerde aynı adresleri kullanmaya çalışan yapılar neden çakışmıyor? Neden her process’in kendine ait ayrı bir bellek ortamı varmış gibi görünüyor?
Bir de buraya nasıl geldik? execve‘nin mevcut process’i yeni bir programla değiştiren bir syscall olduğunu artık biliyoruz, ama bu hâlâ birden fazla process’in nasıl ortaya çıktığını açıklamıyor. Daha da önemlisi, ilk programın nasıl başladığını hiç açıklamıyor. Diğer bütün yumurtaları yumurtlayan ilk tavuk hangi process?
Yolculuğun sonuna yaklaşıyoruz. Bu iki soruya da cevap verdiğimizde, bilgisayarının açılıştan şu anda kullandığın yazılıma kadar nasıl geldiğine dair neredeyse tam bir resmimiz olacak.
Bellek Aslında Sahte
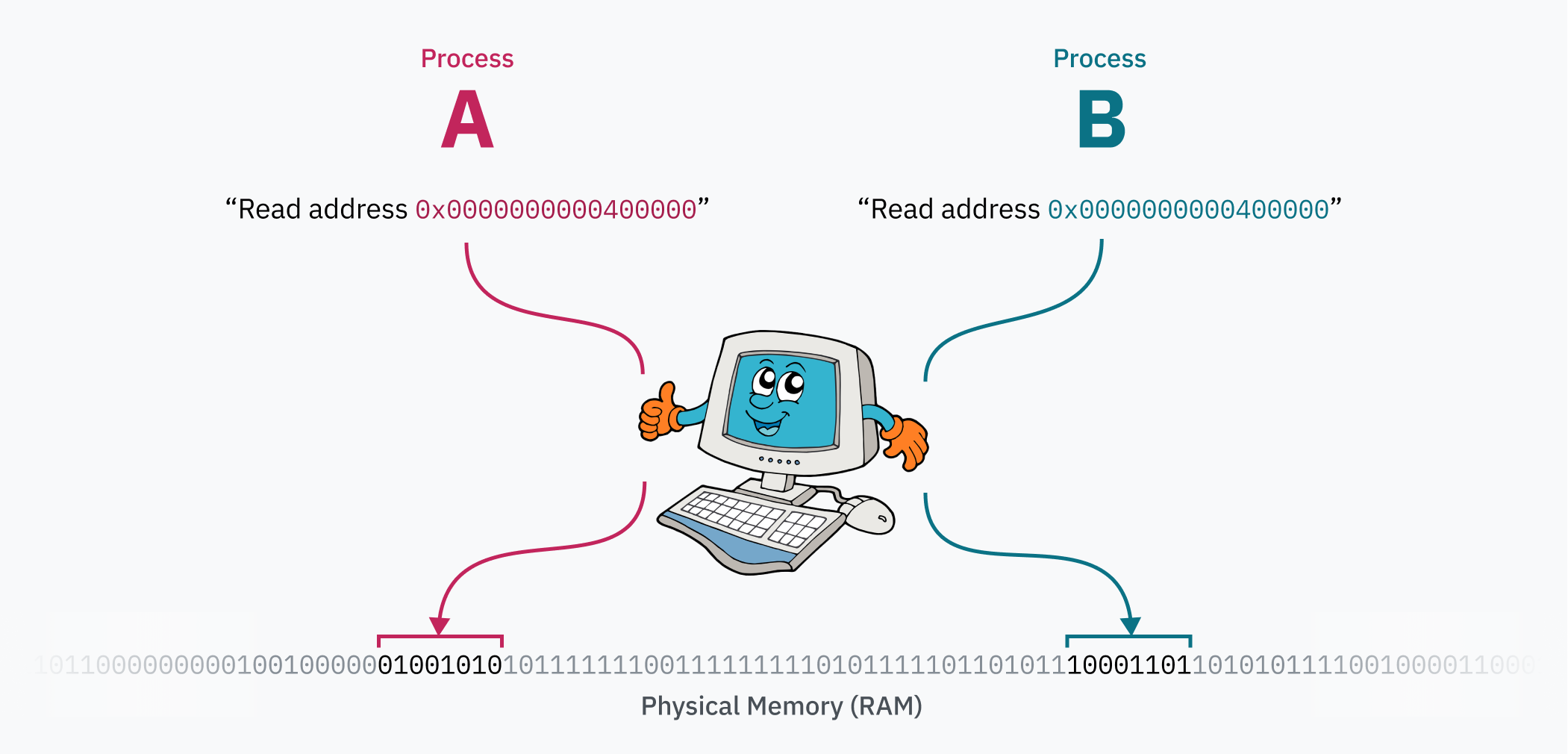
Gelelim belleğe. CPU bir bellek adresinden okuma ya da o adrese yazma yaptığında, bunun aslında doğrudan physical memory‘deki (RAM’deki) o noktaya gitmediği ortaya çıkıyor. Bunun yerine, CPU önce virtual memory alanındaki bir konuma erişiyor.
CPU, memory management unit (MMU) denen bir çiple konuşur. MMU, sanal adresleri RAM’deki fiziksel adreslere çeviren bir sözlük gibi davranır. CPU’ya 0xfffaf54834067fe2 adresinden okuma yap denildiğinde, CPU önce MMU’ya gidip “bunu çevir” der. MMU eşleşen fiziksel adresin 0x53a4b64a90179fe2 olduğunu bulur ve bu sonucu CPU’ya verir. CPU da artık RAM’deki gerçek konuma erişebilir.
Bilgisayar ilk açıldığında bellek erişimleri doğrudan fiziksel RAM’e gider. Çok geçmeden işletim sistemi bu çeviri sözlüğünü kurar ve CPU’ya MMU üzerinden çalışmaya başlamasını söyler.
Bu sözlüğe aslında page table denir; her bellek erişimini çeviren mekanizmanın adına da paging denir. Page table içindeki girdiler page olarak adlandırılır ve her biri sanal bellek alanındaki belirli bir parçanın RAM’de nereye karşılık geldiğini söyler. Bu parçalar sabit boyuttadır ve boyut mimariye göre değişir. x86-64’ün varsayılan page boyutu 4 KiB’dir; yani her page, 4096 baytlık bir blok için eşleme tutar.
Başka bir deyişle, 4 KiB paging kullanıldığında bir adresin en düşük 12 biti MMU çevirisinden önce de sonra da aynı kalır. Bunun sebebi basit: 4096 baytlık bir page içindeki konumu göstermek için 12 bit gerekir.
x86-64 ayrıca işletim sistemlerinin 2 MiB ya da 4 GiB gibi daha büyük page boyutlarını etkinleştirmesine de izin verir. Bu, adres çevirisini hızlandırabilir ama bellek parçalanmasını ve israfı artırabilir. Page ne kadar büyükse, adresin MMU tarafından çevrilmesi gereken kısmı o kadar küçülür.
Page table’ın kendisi de RAM’de tutulur. Milyonlarca girdi içerebilse bile her bir girdi yalnızca birkaç bayt civarında olduğundan, page table tek başına korkunç boyutlara ulaşmaz.
Boot sırasında paging’i etkinleştirmek için kernel önce RAM’de page table’ı kurar. Ardından page table’ın başlangıç adresini, page table base register (PTBR) denen register’a yazar. Son adımda da tüm bellek erişimlerinin MMU üzerinden çevrilmesi için paging’i etkinleştirir. x86-64’te bu yapı büyük ölçüde CR3 ve ilgili kontrol bitleri üzerinden yönetilir.
Paging’in asıl büyüsü, bilgisayar çalışırken page table’ın değiştirilebilmesidir. Her process’in izole bir bellek alanına sahip olması tam da böyle mümkün olur. İşletim sistemi context switch yaparken yaptığı kritik işlerden biri, sanal bellek alanını fiziksel bellekte başka bir yere yeniden eşlemektir. Diyelim iki process var: A process’inin kodu ve verileri 0x0000000000400000 adresinden erişiliyor olabilir; B process’i de kendi kodunu ve verisini aynı sanal adresten görüyor olabilir. Bu iki process aslında aynı adres aralığı için kavga etmez, çünkü bu sanal adresler fiziksel bellekte farklı yerlere çözülür. Kernel, process değişiminde bu eşlemeyi değiştirir.
Bir not: lanetli bir ELF gerçeği
Belirli koşullarda binfmt_elf, belleğin ilk page’ini sıfırlarla eşlemek zorunda kalır. ELF’yi destekleyen ilk sistemlerden biri olan 1988 tarihli UNIX System V Release 4.0 (SVr4) için yazılmış bazı programlar, null pointer’ın okunabilir olmasına dayanır. Ve bir şekilde bazı programlar hâlâ bu davranışı bekliyor.
“Bunun nedenini soruyorsunuz??? Çünkü SVr4, page 0’ı salt okunur şekilde eşliyor ve bazı uygulamalar buna ‘bağımlı’. Bunları yeniden derleme şansımız olmadığı için SVr4 davranışını taklit ediyoruz. İç çek.”
Evet. İç çek.
Paging ile Güvenlik
Paging’in sağladığı process izolasyonu yalnızca kod ergonomisini iyileştirmez; aynı zamanda güçlü bir güvenlik katmanı oluşturur. Process’lerin birbirinin belleğine erişememesi, makalenin başındaki önemli sorulardan birini cevaplar:
Programlar doğrudan CPU üzerinde çalışıyorsa ve CPU doğrudan RAM’e erişebiliyorsa, neden başka process’lerin belleğine ya da Allah korusun kernel belleğine erişemiyorlar?
Bunu sanki haftalar önce sormuşuz gibi geliyor, değil mi?
Peki kernel belleği ne olacak? Öncelikle kernel’ın, çalışan tüm process’leri ve page table’ın kendisini takip etmek için kendi verilerine ihtiyacı var. Bir hardware interrupt, software interrupt ya da syscall tetiklendiğinde CPU kernel mode’a geçtiğinde, kernel kodunun bu belleğe erişebilmesi gerekir.
Linux’un yaklaşımı, sanal bellek alanının üst yarısını kalıcı olarak kernel’a ayırmaktır; bu yüzden Linux için higher-half kernel ifadesi kullanılır. Windows da benzer bir yaklaşım izler. macOS tarafı ise… birazdahakarmaşık ve okurken beynimin kulaklarımdan akmasına neden oldu.
User-space process’lerin kernel belleğini okuyabilmesi ya da yazabilmesi çok kötü olurdu; bu yüzden paging ikinci bir güvenlik katmanı daha sağlar: her page için izin bayrakları tutulur. Bir bayrak, page’in yazılabilir mi yoksa yalnızca okunabilir mi olduğunu söyler. Başka bir bayrak ise bu page’e yalnızca kernel mode’dan erişilebileceğini belirtir. Kernel space’in tamamı, işte bu izinler sayesinde user-space programları için fiilen erişilemez hâle gelir. Teknik olarak eşleme vardır, ama izin yoktur.
Page table’ın kendisi de aslında kernel belleğinde durur. Timer chip bir hardware interrupt tetikleyip context switch başlattığında, CPU ayrıcalık seviyesini kernel mode’a çıkarır ve Linux kernel koduna atlar. Kernel mode’da olduğu için CPU artık korumalı kernel bellek bölgesine erişebilir. Kernel, page table’ı güncelleyip sanal belleğin alt yarısını yeni process için yeniden eşler. User mode’a geri dönüldüğünde bu erişim tekrar kapanır.
Kısacası, neredeyse her bellek erişimi MMU’dan geçer. Interrupt descriptor table içindeki handler adresleri bile aslında kernel’ın sanal adres alanına işaret eder.
Hierarchical Paging ve Diğer Optimizasyonlar
64-bit sistemlerde bellek adresleri 64 bit uzunluğundadır; bu da teorik sanal adres alanının devasa bir 16 exbibyte olabileceği anlamına gelir. Bu sayı, bugün var olan ya da yakın gelecekte var olacak makinelerin çok ötesindedir. Bildiğim kadarıyla tek bir sistemdeki en yüksek RAM miktarlarından biri, 1,5 petabayttan fazla belleğe sahip Blue Waters süper bilgisayarı idi. Bu bile 16 EiB’nin yüzde biri bile etmiyor.
Sanal adres alanındaki her 4 KiB blok için page table’da ayrı bir girdi gerektiğini düşün. Bu durumda 4.503.599.627.370.496 page table girdisine ihtiyacın olurdu. Her girdi 8 bayt ise, sadece page table’ı saklamak için 32 pebibyte RAM gerekirdi. Evet, bu sayı gerçek makinelerdeki toplam RAM miktarından bile absürt derecede büyük.
Bir not: neden bu kadar tuhaf birimler kullanıyorum?
Bunun nadir ve biraz çirkin göründüğünü biliyorum, ama ikili tabanlı bayt boyutlarıyla (2’nin kuvvetleri) onluk SI birimlerini ayırmanın önemli olduğunu düşünüyorum. Bir kilobyte, yani kB, 1000 bayttır. Bir kibibyte, yani KiB, 1024 bayttır. CPU’lar ve bellek adresleri bağlamında sayılar çoğu zaman 2’nin kuvvetleriyle ilerlediği için bu ayrım bana anlamlı geliyor.
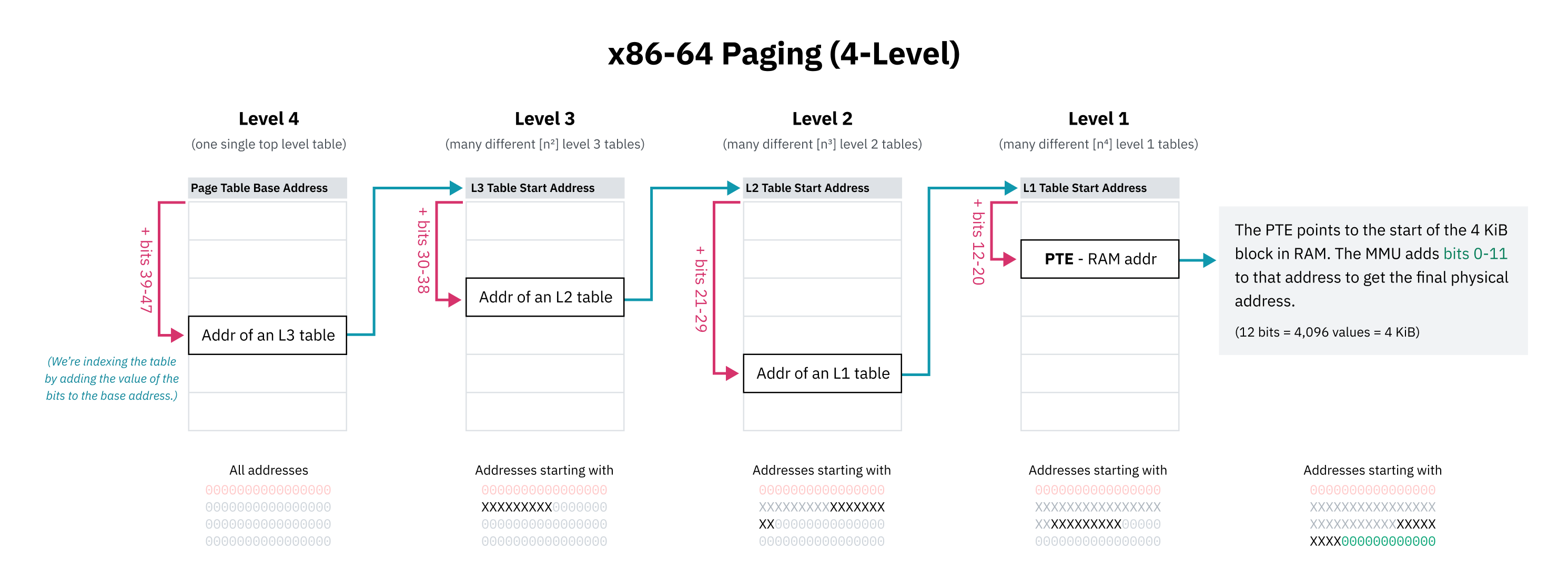
Sanal bellek alanının tamamı için düz bir page table tutmak imkânsız, ya da en azından korkunç derecede verimsiz olacağı için, CPU mimarileri hierarchical paging kullanır. Bu modelde, tek bir dev tablo yerine farklı ayrıntı seviyelerinde birden çok page table katmanı bulunur. Üst katmanlar büyük bellek bloklarını kapsar ve daha küçük aralıklar için alt tablolara işaret eder. 4 KiB page’lere karşılık gelen tek tek girdiler ağacın yapraklarıdır.
x86-64 tarihsel olarak 4 seviyeli hierarchical paging kullandı. Bu düzende, her page table girişi adresin bir kısmıyla indekslenir. En üst anlamlı bitler bir önek gibi davranır; böylece o girdi bu bitlerle başlayan tüm adres aralığını temsil eder. Sonra sıradaki bit kümesi alt tablonun içinde bir sonraki adımı belirler ve bu böyle devam eder.
x86-64’ün 4 seviyeli paging tasarımında, sanal işaretçilerin ilk 16 biti de fiilen göz ardı edilir. 48 bitlik sanal adres alanı 128 TiB eder ve bunun yeterince büyük olduğu varsayılmıştır. (Tam 64 bit kullansan sayı 16 EiB olurdu ki, gereksiz derecede büyüktür.)
İlk 16 bitin atlanması şu anlama gelir: page table’ın ilk seviyesini indeksleyen “en yüksek anlamlı bitler” aslında 63. bitten değil, 47. bitten başlar. Bu yüzden bu bölümün başındaki higher-half kernel diyagramı teknik olarak biraz yalındır; orta nokta, tam 64-bit uzayın değil, fiilen kullanılan daha dar adres uzayının orta noktası üzerinden düşünülmelidir.
Hierarchical paging alan sorununu çözer; çünkü ağacın herhangi bir seviyesinde, bir sonraki tabloya işaret eden pointer boş (0x0) olabilir. Bu sayede page table’ın tüm alt ağaçları atlanabilir; yani eşlenmemiş sanal adres alanı RAM’de yer kaplamaz. CPU, ağacın üst seviyelerinde boş bir giriş gördüğünde erişimi hızlıca başarısız sayabilir. Page table girdilerinde ayrıca “adres geçerli görünse bile kullanılamaz” demeye yarayan bayraklar da vardır.
Bir başka avantaj da, büyük sanal adres bölgelerini topluca değiştirebilmektir. Kernel, bir process için bir fiziksel bellek alanını, başka bir process içinse başka bir alanı hazır tutabilir. Process değiştirirken ağacın en üst düzeyindeki birkaç pointer’ı güncellemek yeterli olur. Eğer tüm eşleme düz bir dizi şeklinde saklansaydı, kernel’ın çok daha fazla girdiyi güncellemesi gerekirdi.
Biraz önce x86-64’ün “tarihsel olarak” 4 seviyeli paging kullandığını söyledim, çünkü yeni işlemciler 5 seviyeli paging destekliyor. 5 seviye, adres alanını 57 bit’e çıkararak 128 PiB sanal alana ulaşmayı sağlıyor. Linux bunu 2017’den beri destekliyor; yeni Windows sunucu sürümleri de benzer şekilde bu dünyaya girdi.
Bir not: fiziksel adres alanı sınırları
Tıpkı işletim sistemlerinin sanal adresler için tüm 64 biti kullanmaması gibi, CPU’lar da fiziksel adresler için tam 64 biti kullanmaz. 4 seviyeli paging döneminde x86-64 CPU’lar genelde 46 bitten fazlasını kullanmıyordu; bu da fiziksel adres alanını 64 TiB ile sınırlıyordu. 5 seviyeli paging ile bu destek 52 bite çıktı ve 4 PiB fiziksel adres alanı mümkün hâle geldi.
İşletim sistemi perspektifinden bakarsan, sanal adres alanının fiziksel adres alanından daha büyük olması avantajlıdır. Linus Torvalds’ın dediği gibi, en az iki kat büyük olması gerekir; on kat büyük olması ise daha da iyidir.
Swapping ve Demand Paging
Bellek erişimi birkaç sebeple başarısız olabilir: adres geçersiz olabilir, page table’da hiç eşlenmemiş olabilir ya da girdi mevcut değil olarak işaretlenmiş olabilir. Bu durumların herhangi birinde MMU, sorunu kernel’ın ele alabilmesi için page fault adlı bir hardware interrupt üretir.
Bazı durumlarda erişim gerçekten geçersizdir ya da yasaktır. Böyle olduğunda kernel büyük ihtimalle programı segmentation fault ile sonlandırır.
Kabuk oturumu
$ ./programSegmentation fault (core dumped)$
Bir not: segfault ontolojisi
“Segmentation fault” farklı bağlamlarda biraz farklı şeyler ifade eder. MMU, yetkisiz bellek erişiminde donanım seviyesinde bir hata üretir; aynı ad, işletim sisteminin bu tür geçersiz erişimler yüzünden programlara gönderdiği sinyal için de kullanılır.
Başka durumlarda ise bellek erişiminin bilerek başarısız olmasına izin verilir; böylece işletim sistemi eksik veriyi yükleyip sonra kontrolü CPU’ya geri verebilir. Örneğin işletim sistemi bir dosyayı, içeriğini daha RAM’e taşımadan sanal belleğe eşleyebilir. Adrese gerçekten erişildiğinde page fault oluşur; kernel da ilgili veriyi diskten RAM’e yükler. Buna demand paging denir.
Bu mekanizma sayesinde mmap gibi syscall’lar tüm dosyaları tembel biçimde sanal belleğe eşleyebilir. Eğer LLaMa.cpp’yi tanıyorsan, Justine Tunney kısa süre önce yükleme mantığını mmap temelli hâle getirerek bunu ciddi biçimde optimize etti. Eğer bilmiyorsan, işlerine bir göz at; Cosmopolitan Libc ve APE epey ilginç.
Bu değişiklik etrafında internette bol miktarda tartışma, daha fazla tartışma ve biraz daha tartışma var. Rastgele internet insanları bana bağırmasın diye bunu not düşüyorum. O dramaların tamamını okumadım ama Justine’in yaptığı işlerin ilginç olduğu fikrim değişmedi.
Bir programı ve kütüphanelerini çalıştırdığında kernel aslında her şeyi baştan RAM’e kopyalamaz. Çoğu durumda yaptığı şey, dosya için bir mmap oluşturmak olur; CPU kodu gerçekten yürütmeye çalıştığında page fault oluşur ve kernel o page’i fiziksel bellekle doldurur.
Demand paging, muhtemelen “swap” ya da “paging” adıyla duyduğun başka bir tekniği de mümkün kılar. İşletim sistemi bellek page’lerini diske yazıp sonra fiziksel RAM’den çıkarabilir; ama bunların sanal adreslerini page table’da tutmaya devam eder. Sonra aynı veri tekrar istenirse, diskten geri yükleyip erişimi yeniden mümkün kılar. Gerekirse diskten gelen sayfaya yer açmak için RAM’deki başka bir page’i swap out etmek zorunda kalabilir. Disk I/O yavaş olduğu için işletim sistemleri iyi page replacement algoritmaları ile bunu mümkün olduğunca az yapmaya çalışır.
Düşünmesi eğlenceli bir hack de şudur: page table içindeki fiziksel adres alanlarını, dosyaların diskteki konumlarını saklamak için kullanabilirsin. MMU zaten “present” biti kapalı bir girdi gördüğünde page fault üreteceği için, o alanların gerçek RAM adresi olmaması bazı tasarımlarda sorun yaratmaz. Her yerde pratik değildir ama akılda tutması keyiflidir.
Bölüm 6: Fork'lar ve COW'lar Hakkında Konuşalım
Son soru: Buraya nasıl geldik? İlk process’ler nereden çıktı?
Bu makalenin son düzlüğündeyiz. Kapanışa yaklaşıyoruz. Birkaç kötü mecaz daha yapıp yolumuza devam edeceğim: yeni ufuklara doğru gidiyoruz, çimenlere dokunacağız ve belki de artık 6. bölüm kadar uzaklarda olmayacağız.
execve, mevcut process‘i değiştirerek yeni bir program başlatıyorsa, tamamen ayrı bir process içinde yeni bir programı nasıl başlatıyorsun? Bilgisayarda birden fazla şey yapmak istiyorsan bu kritik bir yetenek. Bir uygulamaya çift tıkladığında, onu açan program kaybolmaz; yeni uygulama ondan bağımsız şekilde yaşamına devam eder.
Cevap başka bir syscall: fork. Çoklu işlem dünyasının temel taşı budur. fork, mevcut process‘i ve belleğini klonlar, kaydedilmiş instruction pointer’ı olduğu yerde bırakır ve ardından iki process‘in de normal akışına devam etmesine izin verir. Müdahale edilmezse, iki process birbirinden bağımsız ama aynı koddaki farklı yürütmeler olarak devam eder.
Yeni ortaya çıkan process‘e “child”, onu başlatana da “parent” denir. Bir process, fork‘ü birden fazla kez çağırabilir ve böylece birden çok child yaratabilir. Her process‘in, 1’den başlayarak verilen bir process ID‘si (PID) vardır.
Tamamen aynı kodu körlemesine iki kopya hâline getirmek tek başına çok faydalı olmazdı. Bu yüzden fork, parent ve child tarafında farklı değer döndürür. Parent tarafında yeni child process‘in PID’sini döndürür, child tarafında ise 0 döner. Böylece her iki taraf da kendi rolüne göre farklı iş yapabilir.
main.c
pid_t pid =fork();// Kod bu noktadan sonra normal şekilde devam eder,// ama artık iki "özdeş" process üzerinde akmaktadır.//// Özdeş... ama fork'ün döndürdüğü PID hariç.//// Her iki programın da tek ayırt edici işareti budur.if (pid ==0) {// Child process'teyiz.// Bir hesaplama yap ve sonucu parent'a ver!} else {// Parent process'teyiz.// Muhtemelen kaldığımız işe devam ederiz.}
Fork kavramını kafada oturtmak ilk anda biraz garip gelebilir. Bu noktadan sonra anladığını varsayacağım; eğer henüz oturmadıysa, şu korkunç görünümlü web sitesi bu işi aslında fena anlatmıyor.
Her neyse: Unix programları yeni bir program başlatmak istediklerinde tipik olarak önce fork çağırır, ardından child process içinde hemen execve çalıştırır. Buna fork-exec modeli denir. Bir programı başlattığında bilgisayarının yaptığı şey kabaca şuna benzer:
launcher.c
pid_t pid =fork();if (pid ==0) {// Child process'i hemen yeni programla değiştir.execve(...);}// Buraya geldiysek process değiştirilmedi.// Parent process'teyiz. İstersek yeni child'ın PID'si de elimizde.// Parent program burada devam eder...
Moooo!
Fark etmiş olabilirsin: Başka bir program yüklerken bir process’in belleğini yalnızca biraz sonra çöpe atmak üzere tamamen kopyalamak kulağa verimsiz geliyor. Neyse ki elimizde bir MMU var. İşin pahalı kısmı fiziksel RAM’i çoğaltmaktır; page table’ları kopyalamak değildir. Bu yüzden ilk anda hiç RAM kopyalamayız. Yeni process için eski process’in page table’ının bir kopyasını çıkarır ve her iki tarafın da aynı fiziksel bellek bloklarına bakmasını sağlarız.
Ama child process’in parent’tan bağımsız ve yalıtılmış olması gerekir. Child’ın parent belleğine yazabilmesi ya da tam tersi kabul edilebilir değil.
İşte burada COW (copy on write) page’leri devreye girer. COW page’lerinde iki process de aynı fiziksel bellekten okuyabilir; ama içlerinden biri yazmaya kalktığı anda o page RAM içinde kopyalanır. Böylece her iki process de, baştan bütün bellek alanını çoğaltmanın maliyetine katlanmadan ayrı birer bellek görüntüsüne kavuşur. Fork-exec modelinin verimli olmasının nedeni tam olarak budur: Yeni binary yüklenmeden önce eski belleğe yazılmadığı için çoğu durumda gerçek kopyalama hiç gerekmez.
COW, pek çok eğlenceli şey gibi, page fault’lar ve interrupt yönetimiyle uygulanır. fork, parent’ı klonladıktan sonra iki process‘in de tüm page’lerini salt okunur olarak işaretler. Bir program belleğe yazmaya kalktığında, sayfa salt okunur olduğu için yazma başarısız olur. Bu da kernel’ın ele aldığı bir page fault tetikler. Kernel ilgili page’i kopyalar, yazılabilir hâle getirir ve sonra kesmeden çıkıp yazmayı tekrar dener.
A: Tak tak! B: Kim o? A: İneğin sözünü kesen. B: İneğin sözünü kesen ki — C: MOOOOO!
Başlangıçta (Yaratılış 1:1 Olan Değil)
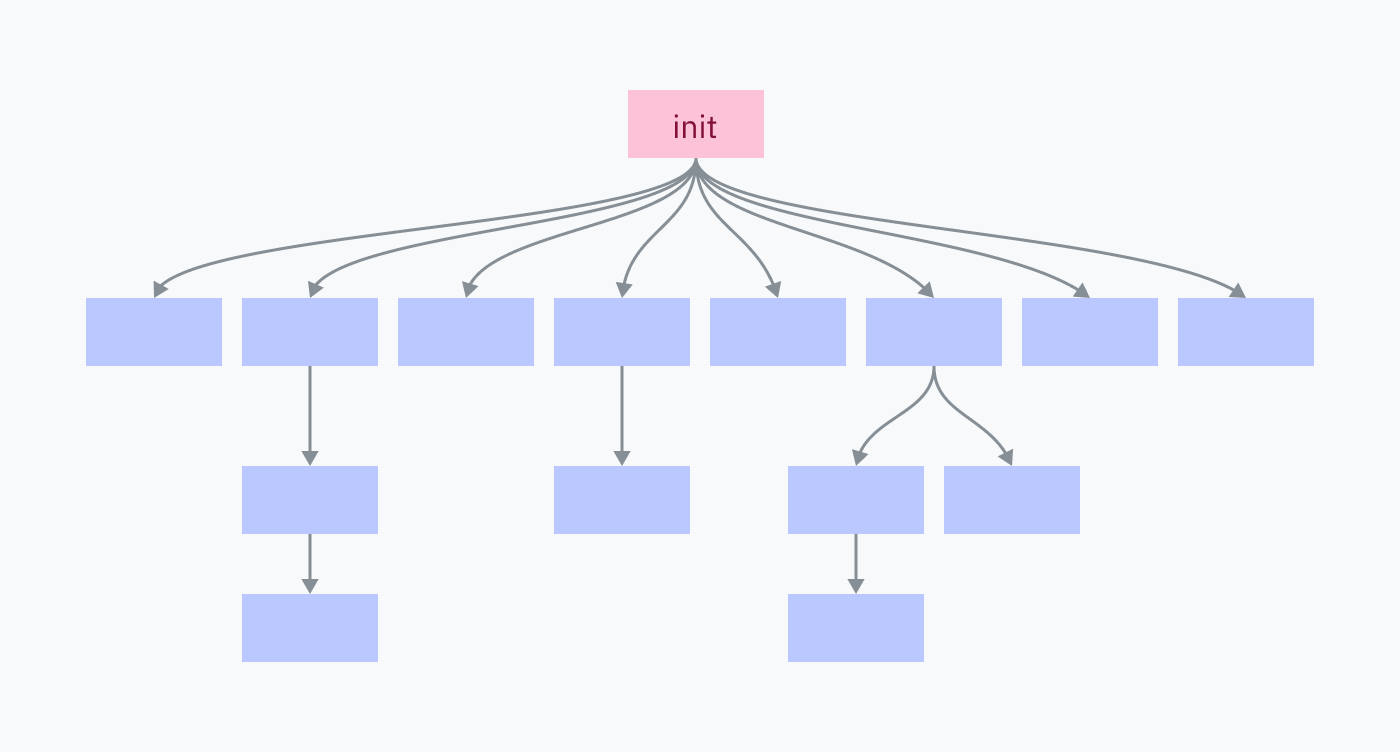
Bilgisayarındaki her process, bir tanesi hariç, başka bir program tarafından fork edilip çalıştırılmıştır: init process. Init process, doğrudan kernel tarafından hazırlanır. Bu, user space’te çalışan ilk programdır ve sistem kapanırken en son ölen de odur.
Anında dramatik siyah ekran görmek ister misin? macOS veya Linux kullanıyorsan çalışmanı kaydet, terminal aç ve init process‘i (PID 1) öldür:
Kabuk oturumu
$ sudo kill 1
Yazar notu: init process‘leriyle ilgili bu kısmın büyük bölümü maalesef yalnızca macOS ve Linux gibi Unix benzeri sistemler için geçerli. Buradan sonrası, çok farklı bir kernel mimarisine sahip Windows’u aynı şekilde anlamanı sağlamayacak.
Tıpkı execve bölümünde olduğu gibi bunu açıkça söylüyorum: NT kernel üzerine başlı başına ayrı bir makale yazılabilir. Şimdilik buna kendimi zor tutuyorum.
Init process, işletim sistemini oluşturan servislerin ve programların büyük bölümünü başlatmaktan sorumludur. Bu programların çoğu da daha sonra kendi çocuklarını üretir.
Init process‘i öldürmek, onun çocuklarını ve onların çocuklarını da zincirleme biçimde öldürerek işletim sistemi oturumunu fiilen kapatır.
Çekirdeğe Dönüş
Linux kernel kodunu kurcalamak Bölüm 3‘te bayağı eğlenceliydi; biraz daha yapalım. Bu kez kernel’ın init process‘i nasıl başlattığına bakacağız.
Bilgisayarın kabaca şu sırayla açılır:
Anakart, bağlı disklerde bootloader denen küçük programı arayan temel bir yazılımla gelir. Bir bootloader seçer, onun makine kodunu RAM’e yükler ve çalıştırır.
Unutma: Henüz tam anlamıyla çalışan bir işletim sistemi dünyasında değiliz. Kernel bir init process başlatana kadar çoklu işlem, syscall ve benzeri üst seviye soyutlamalar aslında ortada yoktur. Boot öncesi bağlamda bir programı “çalıştırmak”, çoğu zaman RAM’deki makine koduna doğrudan atlamak demektir.
Bootloader, kernel’ı bulmak, RAM’e yüklemek ve çalıştırmaktan sorumludur. GRUB gibi bootloader’lar yapılandırılabilir ve hatta birden fazla işletim sistemi arasında seçim yapmana izin verebilir. BootX ve Windows Boot Manager, sırasıyla macOS ve Windows’un yerleşik bootloader’larıdır.
Kernel artık çalışır durumdadır ve interrupt handler’ları kurmak, driver’ları yüklemek, ilk bellek eşlemelerini oluşturmak gibi geniş bir başlatma rutinine girer. Sonunda da ayrıcalık seviyesini user mode’a indirir ve init programını başlatır.
İşte şimdi gerçekten bir işletim sisteminin kullanıcı alanındayız. Init programı init script’lerini çalıştırır, servisleri başlatır ve shell ile grafik arayüz gibi başka programları devreye sokar.
Linux’un Başlatılması
Linux’ta 4. adımın, yani kernel başlangıcının, büyük kısmı init/main.c içindeki start_kernel fonksiyonunda gerçekleşir. Bu fonksiyon yüzlerce satırlık başka init çağrılarıyla doludur; hepsini buraya taşımayacağım ama zamanın varsa göz atmanı öneririm. start_kernel‘ın sonlarında arch_call_rest_init adlı fonksiyon çağrılır:
/* Do the rest non-__init'ed, we're now alive */arch_call_rest_init();
__init ne demek?
start_kernel, asmlinkage __visible void __init __no_sanitize_address start_kernel(void) olarak tanımlanır. __visible, __init ve __no_sanitize_address gibi tuhaf görünen anahtar sözcükler, Linux kernel’ında makrolar aracılığıyla fonksiyonlara ek anlamlar kazandırır.
Bu örnekte __init, boot tamamlandıktan hemen sonra ilgili fonksiyonun ve verisinin bellekten atılabileceğini söyler; amaç yer tasarrufudur.
Bunun nasıl çalıştığını çok detaya girmeden anlatırsak: Linux kernel’ı da sonuçta ELF benzeri bölümlere ayrılır. __init makrosu, kodu normal .text yerine .init.text bölümüne koyan bir derleyici yönergesine genişler. Benzer şekilde __initdata gibi makrolar da verileri özel init bölümlerine yerleştirir.
arch_call_rest_init, temelde yalnızca bir sarmalayıcıdır:
Yorumda “gerisini non-__init olarak yap” denmesinin nedeni, rest_init fonksiyonunun __init ile işaretlenmemiş olmasıdır. Bu da onun, başlangıç belleği temizlenirken serbest bırakılmayacağı anlamına gelir:
/* * We need to spawn init first so that it obtains pid 1, however * the init task will end up wanting to create kthreads, which, if * we schedule it before we create kthreadd, will OOPS. */ pid =user_mode_thread(kernel_init,NULL, CLONE_FS);
user_mode_thread‘a verilen kernel_init fonksiyonu, birkaç son başlangıç adımını tamamladıktan sonra geçerli bir init programı arar. Bu yol üzerinde birçok detay var; bunların çoğunu atlayacağım ama free_initmem çağrısını anmak önemli. Çünkü burası, biraz önce konuştuğumuz .init bölümlerinin gerçekten serbest bırakıldığı yer:
/* * We try each of these until one succeeds. * * The Bourne shell can be used instead of init if we are * trying to recover a really broken machine. */if (execute_command) { ret =run_init_process(execute_command);if (!ret)return0;panic("Requested init %s failed (error %d).", execute_command, ret); }if (CONFIG_DEFAULT_INIT[0] !='\0') { ret =run_init_process(CONFIG_DEFAULT_INIT);if (ret)pr_err("Default init %s failed (error %d)\n", CONFIG_DEFAULT_INIT, ret);elsereturn0; }if (!try_to_run_init_process("/sbin/init") ||!try_to_run_init_process("/etc/init") ||!try_to_run_init_process("/bin/init") ||!try_to_run_init_process("/bin/sh"))return0;panic("No working init found. Try passing init= option to kernel. ""See Linux Documentation/admin-guide/init.rst for guidance.");
Linux’ta init programı neredeyse her zaman /sbin/init konumundadır ya da oraya sembolik bağla işaret edilir. Yaygın init sistemleri arasında systemd, OpenRC ve runit bulunur. Kernel başka hiçbir şey bulamazsa son çare olarak /bin/sh‘i dener. Onu da bulamıyorsa işler gerçekten kötü demektir.
macOS’un da bir init programı vardır: adı launchd‘dir ve /sbin/launchd konumunda durur. Kernel olmadığın için bunu terminalden elle çalıştırmayı denemeni önermem.
Bu noktadan sonra artık boot sürecinin son adımındayız: init process, user space’te çalışıyor ve fork-exec modeliyle başka programları başlatıyor.
Çatal Bellek Eşlemesi
Linux kernel’ının processfork ederken sanal belleğin alt yarısını nasıl yeniden eşlediğini merak ettim, o yüzden biraz daha kurcaladım. kernel/fork.c, fork sürecinin büyük kısmını içeriyor gibi görünüyor. Dosyanın başındaki yorum beni doğru yere yönlendirdi:
/* * 'fork.c' contains the help-routines for the 'fork' system call * (see also entry.S and others). * Fork is rather simple, once you get the hang of it, but the memory * management can be a bitch. See 'mm/memory.c': 'copy_page_range()' */
Bu yoruma bakılırsa, copy_page_range adlı fonksiyon bellek eşlemesini kopyalayan kritik parçalardan biri. Çağırdığı fonksiyonlara bakınca, page’lerin COW hâline getirilmesi için salt okunur olarak işaretlenmesinin de bu yol üzerinde yapıldığını görüyorsun. Bunun gerekip gerekmediğini anlamak için is_cow_mapping adlı fonksiyona bakılıyor.
is_cow_mapping, include/linux/mm.h içinde tanımlı ve ilgili bellek eşlemesinin flag’lerinin belleğin yazılabilir ama süreçler arasında paylaşılmayan bir alanı işaret edip etmediğini kontrol ediyor. Paylaşılan bellek zaten birlikte kullanılmak üzere tasarlandığından COW gerektirmez. Biraz bitmask büyüsüne hayran kal:
kernel/fork.c‘ye geri dönüp copy_page_range için kısa bir arama yaptığında, bunun dup_mmap içinden çağrıldığını görürsün. dup_mmap de dup_mm tarafından, o da copy_mm tarafından, o da sonunda devasa copy_process fonksiyonu tarafından çağrılır. Yani copy_process, fork‘ün kalbidir. Bir bakıma Unix sistemlerinin program başlatma modelinin merkezi burasıdır: her şey, başlangıçta oluşturulmuş bir şablon sürecin kopyalanıp uyarlanmasıyla ilerler.
Özetle…
Peki… programlar nasıl çalışır?
En düşük seviyede cevap şu: işlemciler aptaldır. Ellerinde bellekte bir işaretçi vardır ve onlara başka yere atlamalarını söyleyen bir talimata rastlamadıkları sürece talimatları art arda yürütürler.
Ama bu akış sadece jump talimatlarıyla değişmez; hardware ve software interrupt’lar da yürütmeyi, önceden belirlenmiş başka bir konuma sıçratarak bozabilir. Tek bir işlemci çekirdeği aynı anda birden fazla programı gerçekten çalıştıramaz, ama timer’lar aracılığıyla tekrar tekrar interrupt üretip kernel’ın farklı instruction pointer’lar arasında geçiş yapmasını sağlayarak bunu ikna edici biçimde taklit edebiliriz.
Programlar, aslında olduklarından çok daha düzenli bir ortamda çalıştıklarına inandırılır. User mode, sistem kaynaklarına doğrudan erişimi keser; sayfalama, bellek alanını yalıtır; syscall’lar ise süreçlerin altında yatan gerçek yürütme bağlamını bilmeden genel G/Ç yapabilmesini sağlar. Syscall dediğimiz şey, CPU’ya “kernel’ın önceden belirlediği şu kod yoluna git” diyen talimatlardır.
Ama… programlar nasıl çalışır?
Bilgisayar açıldıktan sonra kernel, init process‘i başlatır. Bu, makine kodunun çok fazla donanım ayrıntısıyla uğraşmak zorunda olmadığı ilk yüksek seviyeli programdır. Init, bilgisayarının grafik ortamını ve geri kalan servisleri başlatır; yani diğer yazılımların dünyaya gelmesinden sorumlu ana ebeveyndir.
Bir programı başlatmak için init ya da başka bir process önce fork ile kendini klonlar. Bu klonlama verimlidir; çünkü page’ler COW olarak paylaşılır ve fiziksel RAM’i baştan sona kopyalamak gerekmez. Linux tarafında bu hikâyenin büyük kısmı copy_process çevresinde akar.
Ardından child process, gerekirse parent’tan farklı yola sapar. Yeni programı gerçekten başlatmak istediğinde exec ailesinden bir syscall çağırır ve kernel’dan mevcut process’i yeni programla değiştirmesini ister.
Bu yeni program çoğu zaman bir ELF dosyasıdır. Kernel, ELF’yi ayrıştırıp kodun ve verinin yeni sanal bellek düzeninde nereye yükleneceğini belirler. Program dynamic linked ise, gerekirse ELF interpreter’ı da devreye girer.
Son adımda kernel yeni sanal bellek eşlemesini kurar ve user space’e geri döner. Pratikte bu, CPU’nun instruction pointer’ını yeni programın kodunun başlangıcına ayarlamak demektir. Ve işte, program gerçekten çalışmaya başlar.
Bölüm 7: Son Söz
Tebrikler. Artık “sen”i CPU’nun içine epey sağlam bir şekilde yerleştirmiş olduk. Umarım keyif almışsındır.
Kapanırken tekrar vurgulamak istediğim şey şu: Bu makaledeki bilgiler gerçek ve yaşayan şeyler. Bir dahaki sefere bilgisayarının nasıl aynı anda birden fazla uygulama çalıştırabildiğini düşündüğünde, umarım timer chip’leri ve hardware interrupt’ları gözünün önüne gelir. Süslü bir programlama diliyle bir şey yazıp linker hatası aldığında, o linker’ın aslında ne yapmaya çalıştığını da biraz olsun hissedersin.
Bu makaledeki herhangi bir bölümle ilgili sorun, soru ya da düzeltmen varsa bana lexi@hackclub.com adresinden yazabilir veya GitHub’da issue ya da PR açabilirsin.
… ama dur, daha bitmedi.
Bonus: C Kavramlarını Türkçeleştirmek
Kendin low-level programlama yaptıysan, muhtemelen stack’in ve heap’in ne olduğunu biliyorsundur; büyük ihtimalle malloc da kullanmışsındır. Ama bunların sistem içinde nasıl uygulandığını çok düşünmemiş olabilirsin.
Öncelikle, bir thread’in stack’i sanal belleğin üst kısımlarında bir yere eşlenmiş sabit büyüklükte bir bellek alanıdır. Çoğu mimaride (hepsinde değil), stack pointer stack alanının tepesinden başlar ve büyüdükçe aşağı doğru ilerler. Eşlenmiş stack alanının tamamı için fiziksel bellek baştan ayrılmaz; bunun yerine, stack frame’lerine gerçekten ihtiyaç duyuldukça belleği tahsis etmek için demand paging kullanılır.
malloc gibi heap allocation fonksiyonlarının syscall olmaması ilk başta şaşırtıcı gelebilir. Heap yönetimi aslında libc implementasyonu tarafından sağlanır. malloc, free ve benzerleri kendi içinde epey karmaşık prosedürlerdir; libc, bellek eşleme detaylarını kendisi takip eder. User-space heap allocator’ı bunun için temelde mmap ve sbrk gibi syscall’lara başvurur.
Bonus: Küçük Notlar
Bunları ana akışta koyacak tutarlı bir yer bulamadım ama ilginçler, o yüzden buraya bırakıyorum.
Linux kullanıcılarının çoğunun yeterince ilginç bir hayatı vardır; page table’ların kernel içinde nasıl temsil edildiğini hayal etmeye fazla zaman ayırmazlar.
Hardware interrupt’lar için alternatif bir görselleştirme:
Bazı syscall’ların kernel space’e sıçramak yerine vDSO adlı bir teknik kullandığını da not düşeyim. Burada buna girmeye vaktim olmadı ama konu oldukça ilginç; istersen buradan, buradan ve buradan devam edebilirsin.
Unix’e özgü detaylar konusunda son bir dürüstlük notu: anlatının önemli bir kısmı Unix dünyasına ait. macOS ya da Linux kullanıyorsan bu gayet iyi, ama aynı CPU mimarisi üzerinde dursa bile Windows’un programları nasıl yürüttüğü ya da syscall’ları nasıl yönettiği hakkında sana doğrudan aynı resmi vermez. İleride bu işin Windows tarafını anlatan ayrı bir yazı yazmayı çok isterim.
Teşekkür
Bu makaleyi yazarken GPT-3.5 ve GPT-4 ile yeterince konuştum. Bana bolca yanlış bilgi verdiler ve söylediklerinin çoğu işe yaramazdı; ama bazı düğümleri çözmede gerçekten yardımcı oldukları anlar da oldu. Sınırlarını biliyorsan ve söyledikleri her şeye son derece şüpheyle yaklaşıyorsan, LLM yardımı net biçimde faydalı olabilir. Yine de yazı yazmakta berbattırlar. Yazıyı senin yerine onların yazmasına izin verme.
Daha da önemlisi; beni düzelten, cesaretlendiren ve birlikte düşünmeme yardım eden herkese teşekkür ederim. Özellikle Ani, B, Ben, Caleb, Kara, polypixeldev, Pradyun, Spencer, Nicky (Bölüm 4‘teki harika elfi çizen kişi) ve sevgili ebeveynlerime minnettarım.
Eğer gençsen, bilgisayarları seviyorsan ve henüz Hack Club Slack‘e katılmadıysan, bence hemen katılmalısın. Düşüncelerimi paylaşabildiğim ve ilerleme kaydedebildiğim böyle bir topluluk olmasaydı bu makaleyi yazamazdım. Eğer genç değilsen, bunları yapmaya devam edebilmemiz için bize destek olabilirsin.
Bu makaledeki çizimlerin tamamı Figma‘da üretildi. Yazım ve düzenleme için Obsidian kullandım; zaman zaman metni cilalamak için Vale da devreye girdi. Makalenin Markdown kaynağı GitHub’da açık ve gelecekteki düzeltmelere açık; bütün çizimler de bir Figma Community sayfasında yayınlanıyor.
Ek Okumalar
Bilgisayarların düşük seviyede nasıl çalıştığını ve kodun makineye nasıl çevrildiğini daha derinlemesine incelemek istersen, Fabien Sanglard’ın web sitesini şiddetle tavsiye ederim. Bu adaptasyonun ruhuna en uygun tamamlayıcı kaynaklardan biridir.