Bölüm 1: Başlamadan Önce
CPU'ya“Sen”iKatmak yazısının parçası: bilgisayarının programları nasıl çalıştırdığına doğru inen uzun bir teknik tavşan deliği.
Bilgisayarlar hakkında konuşurken sürekli karşımıza çıkan bazı kelimeler var: bit, byte, bellek adresi, assembly… Eğer bunlar sana yabancı geliyorsa endişelenme. Bu bölüm tam olarak bunun için var. Sonraki bölümlere atlama; buradaki her kavram bir sonrakinin temeli.
Bu bölümde neyi çözüyoruz?
- Bilgisayarların neden sadece 0 ve 1 anladığını göreceğiz.
- Bit, byte, binary ve hexadecimal kavramlarını pratikleştireceğiz.
- Bellek adresi fikrini kafaya oturtacağız.
- Assembly ile yüksek seviye diller arasındaki farkı netleştireceğiz.
Neden Sadece 0 ve 1?
Bilgisayarların içinde milyarlarca minik anahtar var: transistörler. Transistörleri tek başına “bir bitlik kutu” gibi değil, lojik kapıları ve bellek hücrelerini kuran anahtarlama elemanları gibi düşünmek daha doğru olur. Bir devrede akımın geçmesine izin vererek ya da engelleyerek iki kararlı durumu temsil ederler; bu iki durum da soyut düzeyde 0 ve 1 olarak okunur. Tüm hesaplamalar, tüm videolar, tüm oyunlar, hatta şu an okuduğun bu cümle bile — hepsi bu iki durumun kontrollü kombinasyonlarından oluşur.
Günümüz işlemcilerinde milyarlarca transistör vardır; örneğin Apple M3 çipinde yaklaşık 25 milyar transistör bulunur. Ama “bir transistör = bir bit” genellemesi yanıltıcıdır: SRAM’de bir bit tipik olarak birkaç transistörlü bir latch ile, DRAM’de ise transistör + kapasitör hücresiyle temsil edilir. Transistör temel tuğladır; bit, bu tuğlalarla kurulan devrenin tuttuğu anlamdır.
Bu temel kapı mantığını biraz daha somutlaştıralım. Aşağıdaki diyagram, Boolean operatörlerin (AND, OR, NOT, XOR vb.) nasıl çalıştığını ve bu operatörlerin lojik kapılarla nasıl temsil edildiğini özetliyor. Her kapı, bir veya daha fazla giriş sinyalini alıp tek bir çıkış sinyali üretir; tüm dijital hesaplama bu basit kapıların birleşiminden inşa edilir.
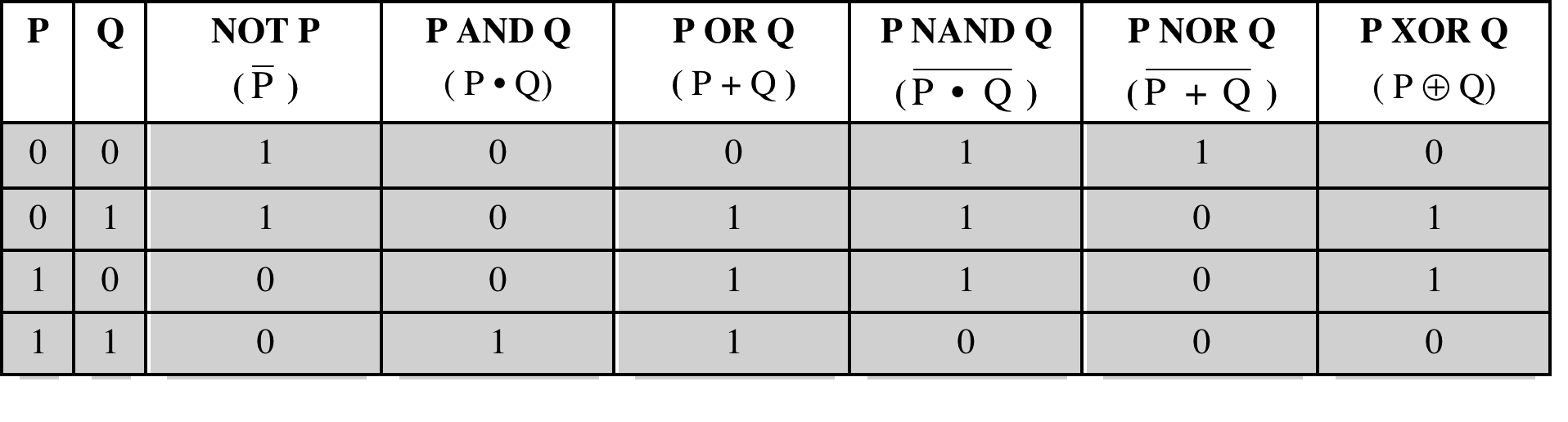
Kaynak: William Stallings, Computer Organization and Architecture, Ch. 11 — Digital Logic, Slide 5.
Bit ve Byte
- Bit: En küçük bilgi birimi. 0 veya 1.
- Byte: 8 bit’in bir araya gelmesi. 1 byte = 8 bit.
Neden 8? Bunun tek bir temiz sebebi yok; tarihsel standardizasyonun sonucu. ASCII 7 bit ile 128 karakteri temsil edebiliyordu, birçok sistem 8. biti parity/hata kontrolü veya genişletilmiş karakterler için kullandı. IBM System/360 gibi etkili mimarilerde 8 bitlik byte’ın yerleşmesi ve donanım/yazılım ekosisteminin buna göre büyümesiyle 1 byte = 8 bit pratik standart hâline geldi.
| Terim | Değer |
|---|---|
| 1 byte | 8 bit |
| 1 kilobyte (kB) | 1.000 byte |
| 1 kibibyte (KiB) | 1.024 byte |
| 1 megabyte (MB) | 1.000.000 byte |
| 1 mebibyte (MiB) | 1.024 × 1.024 byte |
Bu makalede bellek boyutları bağlamında genelde kibibyte (KiB), mebibyte (MiB) gibi ikili tabanlı birimleri kullanacağız. Çünkü bilgisayarlar 2’nin kuvvetleriyle düşünür.
İkilik (Binary) Sistem
İnsanlar onluk (decimal) sistem kullanır: 0’dan 9’a kadar rakamlar. Bilgisayar donanımı ise iki durumlu lojik üzerine kurulduğu için ikilik (binary) sistemi doğal kullanır: sadece 0 ve 1. Boolean logic tarafında bu iki değer false/true, devre tarafında ise düşük/yüksek voltaj aralıkları gibi temsil edilir; önemli olan fiziksel ayrıntı değil, iki güvenilir durumun ayırt edilebilmesidir.
| Decimal | Binary |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 1000 |
Binary’deki her basamak, 2’nin bir kuvvetini temsil eder. Sağdan sola: 2⁰, 2¹, 2², 2³…
Örneğin 1011 binary:
- 1 × 2³ = 8
- 0 × 2² = 0
- 1 × 2¹ = 2
- 1 × 2⁰ = 1
- Toplam: 11 (decimal)
Hexadecimal (Onaltılık) Sistem
Binary yazıları uzun olur. Örneğin 255 decimal = 11111111 binary. Bunu kısaltmak için hexadecimal (onaltılık) kullanılır: 0-9 ve A-F (10-15).
| Decimal | Binary | Hex |
|---|---|---|
| 0 | 0000 | 0 |
| 10 | 1010 | A |
| 15 | 1111 | F |
| 16 | 0001 0000 | 10 |
| 255 | 1111 1111 | FF |
Bir byte (8 bit) her zaman iki hex karakteriyle gösterilebilir. Bu yüzden bellek dökümleri ve makine kodları genelde hex formatında yazılır.
ASCII ve Karakterlerin Sayı Hâli
Bilgisayarlar metni nasıl saklar? Her harf, rakam ve sembole bir sayı atanır. En temel standart ASCII‘dir (American Standard Code for Information Interchange). 128 karakter tanımlar.
| Karakter | Decimal | Hex |
|---|---|---|
| ‘A’ | 65 | 41 |
| ‘a’ | 97 | 61 |
| ‘0’ | 48 | 30 |
| ’ ’ (boşluk) | 32 | 20 |
ASCII yetersiz kalınca (Türkçe karakterler, Çince vb.) Unicode ve UTF-8 devreye girdi. UTF-8, bir karakteri 1-4 byte arasında değişen uzunlukta temsil eder ve dünya üzerindeki neredeyse tüm yazı sistemlerini destekler.
Bir yana: Unicode ve UTF-8’in İçyüzü
Unicode, her karaktere evrensel bir numara (code point) atayan bir standarttır. Örneğin ‘A’ = U+0041, ‘ö’ = U+00F6, ’𐍈’ = U+10348. UTF-8 ise bu numaraları byte’lara çevirme yöntemidir.
UTF-8 neden değişken uzunluklu? Çünkü 1.1 milyondan fazla karakteri tek byte’la (0-255) ifade edemezsin. Ama aynı zamanda İngilizce metinlerin %90’ı ASCII karakterlerden oluşur; bunları tek byte’ta tutmak boş yere yer israfı olmaz. İşte UTF-8’in zekası burada:
- U+0000 - U+007F (ASCII): 1 byte.
0xxxxxxx- U+0080 - U+07FF: 2 byte.
110xxxxx 10xxxxxx- U+0800 - U+FFFF: 3 byte.
1110xxxx 10xxxxxx 10xxxxxx- U+10000 - U+10FFFF: 4 byte.
11110xxx 10xxxxxx 10xxxxxx 10xxxxxxASCII karakterleriyle tam uyumlu olması, eski C programlarının ve protokollerin çalışmaya devam etmesini sağlar. UTF-8, bir karakterin ilk byte’ından kaç byte süreceğini anlayabilirsin; bu sayede metin boyunca ilerlerken her zaman doğru sınıra denk gelirsin (self-synchronizing). UTF-16 gibi sabit genişlikli kodlamalar ise 16 bit’in yetmediği durumlarda “surrogate pair” denen iki 16 bitlik birim kullanır; bu da metin işlemeyi daha karmaşık hâle getirir.
Endianness: Byte Sıralaması
Bir sayı birden fazla byte tutuyorsa, bu byte’ların bellekte hangi sırada saklanacağı önemli hâle gelir. İşte tam bu noktada endianness (byte sıralaması) devreye girer.
- Little-endian: En düşük değerli byte (LSB), en düşük bellek adresinde saklanır. Intel x86 ve x86-64 mimarileri little-endian kullanır.
- Big-endian: En yüksek değerli byte (MSB), en düşük bellek adresinde saklanır. Ağ protokolleri (TCP/IP) ve eski Motorola/PowerPC mimarileri big-endian kullanır.
“Endian” kelimesi, Jonathan Swift’in Gulliver’in Gezileri kitabından gelir: Yumurtanın hangi ucundan kırılacağı konusundaki savaş. 1981’de Danny Cohen bu terimleri bilgisayar bilimine taşımıştır.
Neden x86 little-endian? Tarihsel bir tesadüf aslında. Intel’in ilk mikroişlemcisi 8008, seri hesaplama mantığıyla uyumlu olması için en düşük anlamlı biti önce işleyecek şekilde tasarlanmıştı. O günden beri Intel ailesi little-endian kalmaya devam etti; taşıyıcı zincirleme (carry propagation) için aritmetik işlemlerde de avantajlıdır.
Bir örnek: 32 bitlik 0x12345678 sayısı bellekte nasıl durur?
Adres Big-endian Little-endian
0x1000 12 78
0x1001 34 56
0x1002 56 34
0x1003 78 12Aynı veri, aynı adreslerde; sadece okuma sırası farklı. Bir hex dump okurken bu farkı bilmek hayati önemdedir. Ağ üzerinden veri gönderirken big-endian (network byte order) kullanılması standarttır; little-endian bir makine göndermeden önce byte’ları çevirmelidir.
Bellek Adresi: Her Şeyin Bir Numarası Var
Bilgisayarın belleği (RAM), byte’ların yan yana dizildiği dev bir dizi gibidir. Her byte’ın bir adresi (numarası) vardır. Adres 0’dan başlar ve RAM boyutuyla sınırlıdır.
Düşün ki bir apartman var ve her daire bir byte. Apartmanın kapıcısı (CPU) bir daireye ulaşmak için daire numarasını (adres) kullanır.
| Adres | Değer (Hex) | Değer (ASCII) |
|---|---|---|
| 0x1000 | 48 | ‘H’ |
| 0x1001 | 65 | ‘e’ |
| 0x1002 | 6C | ‘l’ |
| 0x1003 | 6C | ‘l’ |
| 0x1004 | 6F | ‘o’ |
Adresler genelde
0xönekiyle hexadecimal olarak yazılır.0x1000= 4096 decimal.
Makine Kodunu Gözlemlemek
Şimdiye kadar öğrendiklerimizi terminalde doğrulayabiliriz. xxd, hexdump ve od gibi araçlar dosyaları ham byte düzeyinde gösterir.
xxd, hex dump için en yaygın kullanılan araçtır. Sol tarafta offset (adres), ortada hex byte’lar, sağda ASCII karşılığı görünür:
echo -n "AB" | xxdÇıktısı şu şekilde olur:
00000000: 4142 AB41 hex = 65 decimal = ‘A’, 42 hex = 66 decimal = ‘B’. echo -n ile son satır karakteri (newline) eklenmedi; sadece ham “AB” string’i işlendi.
Bir binary dosyanın içindeki makine talimatlarını objdump ile assembly olarak okuyabiliriz. /bin/ls gibi yaygın bir programın başındaki talimatlar:
objdump -d /bin/ls | head -20/bin/ls: file format elf64-x86-64
Disassembly of section .init:
0000000000004000 <.init>:
4000: f3 0f 1e fa endbr64
4004: 48 83 ec 08 sub $0x8,%rsp
4008: 48 8b 05 d9 4f 01 00 mov 0x14fd9(%rip),%rax
400f: 48 85 c0 test %rax,%rax
4012: 74 02 je 4016 <...>
4014: ff d0 call *%rax
4016: 48 83 c4 08 add $0x8,%rsp
401a: c3 retSoldaki adresler (4000, 4004…), ortadaki makine kodu (f3 0f 1e fa), sağdaki assembly (endbr64) aynı talimatın üç farklı temsilidir. Bellekte saklanan şey ortadaki byte’lardır; CPU bunları çözüp sağdaki gibi davranır.
Assembly ve Yüksek Seviye Diller
Assembly, CPU’nun anladığı makine koduna çok yakın bir dildir. Her CPU ailesinin (x86, ARM, RISC-V) kendi assembly dili vardır.
; x86-64 assembly örneği
mov rax, 5 ; rax register'ına 5 yaz
add rax, 3 ; rax'a 3 ekleYüksek seviye diller (C, Python, Java, JavaScript) insanlar için daha kolaydır. Derleyici veya yorumlayıcı bu kodu makine koduna çevirir.
// C ile aynı işlem
int x = 5;
x = x + 3;Bir C programı derlendiğinde, önce assembly’ye, oradan da makine koduna (binary) dönüştürülür. Bu makine kodu, CPU’nun talimat olarak okuduğu 0 ve 1 dizisidir.
C’den Makine Koduna: Derleme Pipeline’ı
gcc hello.c -o hello yazdığında aslında tek bir araç çalışmaz; bir pipeline (boru hattı) devreye girer. C kaynağı makine koduna dört aşamada dönüşür:
1. Önişlemci (Preprocessor)
#include, #define gibi direktifleri çözer; başlık dosyalarını içeri aktarır, makroları genişletir, yorumları siler. C dilinin syntax’ını bilmez; sadece metin değiştirme motorudur.
gcc -E hello.c -o hello.i
wc -l hello.i 842 hello.i
<stdio.h>gibi başlıklar binlerce satır genişleyebilir;hello.idosyası orijinal kaynağın çok üzerinde satır içerebilir.
2. Derleyici (Compiler)
Önişlenmiş C kodunu (hello.i) hedef mimariye özgü assembly diline çevirir. Bu aşama optimizasyon, tip kontrolü ve hata raporlamasının gerçekleştiği yerdir.
gcc -S hello.i -o hello.s
cat hello.s .file "hello.c"
.text
.globl main
.type main, @function
main:
pushq %rbp
movq %rsp, %rbp
movl $5, -4(%rbp)
addl $3, -4(%rbp)
movl $0, %eax
popq %rbp
ret
-Sbayrağı (büyük S) derleyiciyi assembly ürettikten sonra durdurur; daha sonraki aşamalara geçmez.
3. Assembler
Assembly metnini (hello.s) ham makine koduna çevirir. Çıktı bir object file (hello.o) olur; bu dosya binary talimatlar içerir ama henüz çalıştırılabilir değildir. Dışarıdan çağrılan fonksiyonların (örn. printf) adresleri henüz boştur.
gcc -c hello.s -o hello.o
file hello.ohello.o: ELF 64-bit LSB relocatable, x86-64, version 14. Bağlayıcı (Linker)
Birden fazla object dosyasını ve sistem kütüphanelerini (örn. libc) bir araya getirir. Tüm sembol referanslarını çözümler, adresleri sabitler ve nihai çalıştırılabilir dosyayı üretir.
gcc hello.o -o hello
file hellohello: ELF 64-bit LSB pie executable, x86-64, version 1Tek komutla tüm pipeline’ı çalıştırmak mümkündür: gcc hello.c -o hello. Ama aşamaları bilmek, derleme hatalarının hangi aşamada oluştuğunu anlamak için kritiktir.
Dış Kaynaklar
- ASCII — Vikipedi
- Unicode — Vikipedi
- Endianness — Vikipedi
- Transistör — Vikipedi
- UTF-8 ve Unicode Standardı — unicode.org
Özet
Peki, ne öğrendik?
- Bilgisayarlar transistörlerin açık/kapalı durumlarıyla (1/0) çalışır.
- 8 bit = 1 byte. Hexadecimal, binary’yi kısaltmak için kullanılır.
- ASCII 128 karakterle yetinir; dünya dilleri için Unicode ve UTF-8 gerekir.
- Çok byte’lı sayılar bellekte little-endian (x86) veya big-endian (ağ) olarak saklanabilir.
- Her byte’ın bellekte bir adresi vardır; hex dump araçlarıyla bu adresleri ve içerikleri gözlemleyebiliriz.
- Assembly CPU’ya yakındır; yüksek seviye diller insana yakındır.
- C kodu derlenirken önişlemci → derleyici → assembler → bağlayıcı pipeline’ından geçer.
- Hepsi sonuçta aynı şeye çıkar: makine kodu, yani 0 ve 1 dizisi.
Bu temelleri attıktan sonra bilgisayarın beyni olan CPU’yu derinlemesine inceleyebiliriz. Sonraki bölümde CPU’nun nasıl talimat çekip çözdüğünü göreceğiz. Daha ileride ise ELF formatı ve makine kodunun belleğe nasıl yerleştiğini adım adım çözüp, gerçek bir programın hayatını baştan sona takip edeceğiz.
Şimdi bilgisayarın temel bileşenlerine — CPU, RAM ve talimat döngüsüne — geçebiliriz.
2. bölüme devam et: Temeller